Mastering Swahili News Classification with LSTM: A Step-by-Step Guide


Introduction
In the dynamic and broad field of artificial intelligence, the UDSM AI Community continues to be a fostering place of innovation, exploration, and collaborative learning. In our latest session, we embarked on an exciting journey into the realm of natural language processing, specifically focusing on Swahili news classification using Long Short-Term Memory (LSTM) networks.
Our collective attempt is not merely a technical quest but a proof to our commitment to pushing the boundaries of AI understanding. And we chose to go with Swahili, a language rich in history and culture, to serves as our medium to explore how we can understand text (news) classification, demonstrating how advanced techniques can unravel meaningful insights from diverse sources.
Session Objective
Our main goal in this session was twofold. First, we wanted to walk you through a real hands-on activity, neatly packed into a Jupyter notebook. This activity is all about using LSTMs to explore how we can use different tokenizers with Swahili text.
Second, we want this to be a space where everyone can join in. We're all about teamwork here. So, we're encouraging you to jump into the code, ask questions, and share your thoughts. Together, we're going to get better at understanding how to play with tokenizers and make sense of the text using our NLP skills.
As we dive into the technical bits, remember, it's not just about the code; it's about growing together, helping each other, and making our AI community even more awesome.
Technical Implementation
In this technical implementation, we explore the process of Swahili news classification using Long Short-Term Memory (LSTM) networks. The project is a collaborative effort within the UDSM AI Community, aiming to showcase effective Swahili news classification techniques to the community members. The focal point of the session was a Jupyter notebook that encapsulated a hands-on technical activity, specifically implementing a Swahili news classification model. This showcased cutting-edge technologies and methodologies in natural language processing. The code was carefully made to correctly classify Swahili news articles, demonstrating best practices in text classification within the field of machine learning.
The session encouraged everyone to check out the Jupyter notebook and understand the code. We'll talk about specific parts of the code here, explaining important methods and steps. Here are the things we did: -
1. Importing Libraries
The journey into Swahili news classification began with the importation of essential libraries. This ensured that the tools needed for data manipulation and model construction are at our fingertips.
# Import necessary libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import OneHotEncoder
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
2. Loading Datasets
To lay the groundwork for our Swahili news classification project, we load the dataset from a CSV file. The dataset, sourced from various Swahili news websites, will be our playground for training and testing the LSTM model
# Load your dataset
data_path = 'data/SwahiliNewsClassificationDataset.csv'
df = pd.read_csv(data_path)
3. Data Preprocessing
Before feeding the data into the model, several preprocessing steps are applied.
A: Normalising Data
The first step in preparing our dataset involves normalising the textual data. This includes removing punctuation, numbers, special characters, stop words, and lemmatising words. The result is a clean and standardised text column.
import re
def normalize_text(text):
# Remove punctuation, numbers, and special characters
text = re.sub(r'[^a-zA-Z\s]', '', text)
# Convert to lowercase
text = text.lower()
return text
# Normalize the text column
df['Text'] = df['content'].apply(normalize_text)
texts = df['Text'].values
labels = df['category'].values
texts[0], labels[0]
B: Converting Labels to Numerical Formats
With the textual data normalised, the next phase is converting the categorical labels into numerical formats. This facilitates the use of these labels in our LSTM model.
# one hot encode the labels
encoder = OneHotEncoder(sparse=False)
labels = encoder.fit_transform(labels.reshape(-1, 1))
encoder.categories_
4. Splitting the Dataset
To ensure the robustness of our LSTM model, we split the dataset into training and testing sets. This segregation allows us to train the model on one subset and evaluate its performance on another.
# Split the dataset into training and testing sets
train_texts, test_texts, train_labels, test_labels = train_test_split(texts, labels, test_size=0.2, random_state=42)
5. Tokenising and Padding Sequences
In this critical phase, we tokenise the words and pad the sequences to prepare the data for the LSTM model. The tokenisation process involves converting words into numerical values, while padding ensures uniformity in the length of our sequences.
max_words = 1000
max_len = 200
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(train_texts)
train_sequences = tokenizer.texts_to_sequences(train_texts)
test_sequences = tokenizer.texts_to_sequences(test_texts)
train_data = pad_sequences(train_sequences, maxlen=max_len)
test_data = pad_sequences(test_sequences, maxlen=max_len)
train_data[0].shape, train_labels[0].shape
6. Building the Model
The heart of our Swahili news classification project lies in the construction of the LSTM model. With layers of embedding, LSTM, and dense structures, we compile the model to enable its training on our preprocessed data.
embedding_dim = 50 # Adjust based on your preferences
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=embedding_dim, input_length=max_len))
model.add(LSTM(100))
model.add(Dense(6, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
batch_size = 32
epochs = 10
history = model.fit(train_data, train_labels, validation_split=0.2, batch_size=batch_size, epochs=epochs)
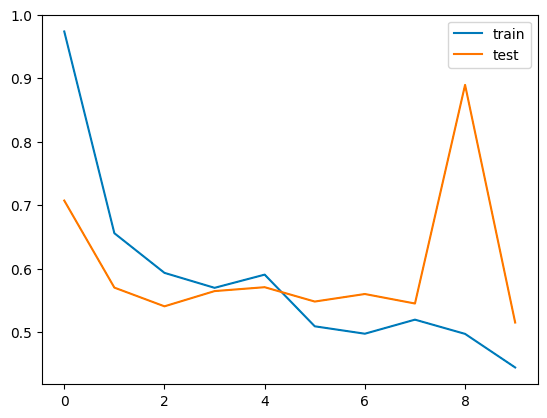
# plot loss and accuracy
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
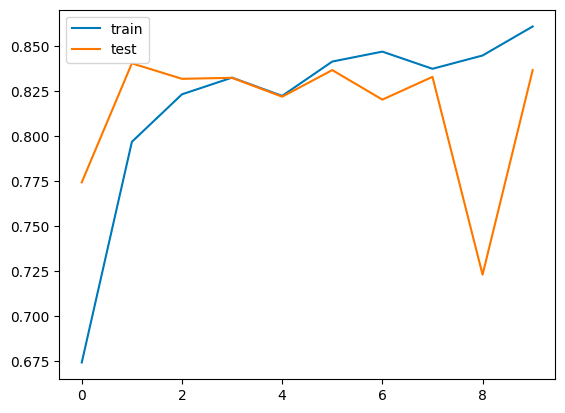
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='test')
plt.legend()
plt.show()
# evaluate the model
loss, accuracy = model.evaluate(test_data, test_labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
# save the model
model.save('models/starter_swahili_news_classification_model.h5')
7. Inferencing the Model
As we conclude our journey, we put our trained model to the test by inferring its predictions on a randomly selected Swahili news headline. The process involves pre-processing the input text and utilising the model to make predictions.
# pre-process for inference
def pre_process(tokenizer, max_len, input_text):
input_sequence = tokenizer.texts_to_sequences([input_text])
input_data = pad_sequences(input_sequence, maxlen=max_len)
return input_data
def classify_news(model, tokenizer, encoder, max_len, input_text):
input_data = pre_process(tokenizer, max_len, input_text)
pred = model.predict(input_data)
# for each input sample, the model returns a vector of probabilities
# return all classes with their corresponding probabilities
result_dict = {}
for i, category in enumerate(encoder.categories_[0]):
result_dict[category] = str(round(pred[0][i] * 100, 2))+'%'
highest_prob = max(result_dict, key=result_dict.get)
return (result_dict, highest_prob)
# pick a random news headline from df
news_ = df.sample(1)
news_headline = news_['Text'].values[0]
news_category = news_['category'].values[0]
result_dict, classified_label = classify_news(model, tokenizer, encoder, max_len, news_headline)
print(f'News headline: {news_headline}')
print(f'Actual category: {news_category}')
print(f'Predicted category: {classified_label}')
print(f'Confidence scores: {result_dict}')
Challenges Encountered
Despite our collective efforts in the session, we ran into some tricky situations. The Swahili language posed a unique challenge due to its complexity, and there wasn't much research available on how to break down its words. We had to rely on methods designed for English, which may not be the best fit for Swahili. Additionally, finding information tailored to the specific structure and rules of Swahili proved to be quite difficult. Nevertheless, our community faced these challenges head-on. Instead of seeing them as roadblocks, we turned them into opportunities to learn and improve. Our shared determination and collaborative spirit continue to shape a supportive and dynamic learning environment within the UDSM AI Community.
Outcomes
As a result of our collective efforts, participants gained valuable insights into tokenisation and various tokenisation methods available. The session served as a rich learning experience, expanding our understanding of how to break down and process words effectively.
Moreover, after training the model, we achieved a notable milestone with a maximum accuracy of 83.78%. This success reflects the effectiveness of our collaborative exploration and dedication during the session. For a visual representation of our progress, detailed screenshots and graphs showcasing the training outcomes are provided below. These visual aids offer a transparent and comprehensive view of our achievements, highlighting the strides we've made in understanding Swahili news classification using LSTM.

CONCLUSION
This step-by-step guide provides a comprehensive overview of the technical implementation, offering both beginner and experienced community members an instructive roadmap for Swahili news classification using LSTM. Each part contributes to the general understanding of the project, from data preprocessing to model inferencing.
In conclusion, the session stood as proof of our community's strength and commitment to sharing knowledge. Guided by the expertise of our members, Edgar Gulay, who led a hands-on task through a Jupyter notebook, everyone had the chance to contribute key ideas and actively engage in the session. As the community looks forward to future sessions, the spirit of collaboration and exploration remains at the forefront.