Is Web Scraping Illegal? Debunking the Myths and Understanding the Legal Landscape
Discover the ins and outs of web scraping legality with our easy-to-understand guide. Learn about compliance, legal considerations, and how to navigate data extraction regulations. Stay informed to ensure your web scraping practices are legal and make the most of your extracted data.

The practice of web scraping has long been a topic of debate, with varying opinions on its legality. While there are instances where web scraping can cross legal boundaries, it is important to recognize that it is not inherently illegal. In this article, we delve into the complex legal landscape surrounding web scraping, shedding light on both its legal and illegal aspects.
By understanding the nuances of this practice, individuals and businesses can make informed decisions while embracing the potential opportunities it presents.
What is Web Scraping?

Web scraping, also known as web harvesting or web data extraction, is a technique that allows individuals or organizations to extract valuable data from websites. It involves automating the process of fetching and parsing website content, extracting specific information, and storing it for further analysis or use.
Web Scraping vs. Web Crawling:
Web scraping: Extracting targeted data from specific web pages.
A valuable alternative to expensive or unavailable APIs for obtaining targeted data from specific web pages, providing a cost-effective solution for data acquisition.
Web crawling: Systematically indexing the entire content of a website.
- Scraping focuses on specific information, while crawling aims to build comprehensive indexes.
- Scraping is used for data analysis and research, while crawling is essential for search engines.
The Negative Effects of Web Scraping on Websites
While web scraping can offer certain benefits, it's essential to be aware of the potential negative impacts it can have on a website. Here are some key negative effects to consider:
Increased Server Load Resembling a DDoS Attack:
- Multiple simultaneous or frequent scraping requests can lead to slower page loading times and decreased website performance.
- Potential Website Downtime: In extreme cases, the cumulative effect of relentless scraping activities can overload the server to the point of complete unavailability, resulting in website downtime.
Loss of Intellectual Property:
- Unauthorized web scraping can lead to the extraction and use of a website's content without permission.
- This can result in the loss of control over intellectual property, including copyrighted material.
- Content misuse or plagiarism can occur when scraped content is republished without proper attribution or authorization.
Data Privacy Concerns:
- Web scraping raises concerns about data privacy, as personal or sensitive information can be extracted without consent.
- It forces website owners to implement robust security measures to protect user data from unauthorized scraping activities.
- Compliance with data protection regulations is essential to safeguard user privacy and prevent data breaches.
Content Scraping and Duplication:
- Web scraping can lead to the duplication of website content.
- Scraped content may be republished on other websites without proper attribution or permission.
- Content duplication can negatively impact the original website's search engine ranking and overall visibility.
The Legal Landscape:
Despite the misconceptions surrounding its legality, it is essential to understand that web scraping itself is not an inherently illegal activity. In fact, it serves as a powerful tool for gathering information and enabling various legitimate use cases.
One of the most significant advantages of web scraping is its ability to empower market researchers to gauge public sentiment on social media platforms. By extracting data from these platforms, analysts can gather valuable insights that help businesses make informed decisions. This legitimate application of web scraping showcases its positive impact on understanding consumer behavior and market trends.
Web scraping has also played a vital role in training our AI systems, including our Sarufi chatbot. By gathering data from various sources, web scraping enables AI models to learn and understand patterns, leading to accurate and intelligent responses. Without web scraping, the development of AI systems like Sarufi would be significantly limited.
In general, web scraping of public data from websites and using it for analysis purposes is considered perfectly legal. Public data refers to information that is accessible to the general public without any restrictions or login requirements. When web scraping is conducted within the boundaries of public data, it serves as a valuable method for extracting and analyzing information.
However, it is crucial to acknowledge that there are instances where web scraping can cross legal boundaries. It is important to adhere to the following rules:
- Compliance with Website Terms of Service (ToS): Respect the rules set by websites you scrape. Some websites explicitly prohibit web scraping in their ToS. By adhering to these terms, you demonstrate ethical conduct.
- Avoid scraping private data: Be cautious when accessing data that requires a username, password, or other credentials for authentication. Scraping such private information without proper authorization is not ethical.
- Respect copyright laws: Do not copy or scrape content that is protected by copyright. This includes text, images, videos, and other creative works. Obtain proper permissions or seek alternative sources for gathering data.
- Follow robots.txt guidelines: Pay attention to a website's robots.txt file, which specifies which parts of the site can be accessed by crawlers. Respect the directives outlined in the file to ensure you only scrape areas permitted by the website owner.
- Mindful of rate limits: Websites may have rate limits in place to prevent excessive scraping and ensure fair resource allocation. Respect these limits to avoid overloading servers and causing disruptions for other users.
- Implement clear data use and retention policies: Clearly define how the scraped data will be used and establish appropriate data retention practices. Ensure that the data is handled responsibly and in accordance with privacy regulations.
- Stay updated on legal and ethical guidelines: Web scraping regulations and best practices can evolve over time. Stay informed about the current legal and ethical landscape surrounding web scraping to ensure your practices align with the latest standards.
Tracing the Legal Journey of Web Scraping: Key Milestones and Precedents,
In 2001, a ruling stated that scraping data from a website, even if unwelcome, may not constitute unauthorized access.
In 2009, Facebook won a copyright suit against a web scraper, setting a precedent for copyright violations associated with scraping.
In 2016, US Congress passed the BOTS Act to target ticket scalping bots, indicating a specific focus on addressing fraudulent activities rather than web scraping as a whole.
In 2017, a judge ruled in favor of hiQ Labs in a lawsuit against LinkedIn, allowing access to publicly available LinkedIn profiles through scraping.
Various legal cases and rulings throughout the years have highlighted the complexity and evolving nature of web scraping's legal landscape.
Myth vs. Fact: Debunking Common Web Scraping Misconceptions
Web scraping is illegal.
Fact: Web scraping is legal. It is a method of extracting data from websites, and its legality just depends on various factors such as the website's terms of service and the intended use of the scraped data.
Web scraping always violates website terms of service.
Fact: While some very few websites explicitly prohibit web scraping in their terms of service, Most of them Do not. It is essential to review each website's terms of service to determine the specific guidelines regarding web scraping.
Web scraping is unethical.
Fact: The ethical implications of web scraping depend on how it is used. When done responsibly and with respect for website owners' rights and privacy concerns, web scraping can serve legitimate purposes such as data analysis, research, and market intelligence.
Web scraping is a security threat.
Fact: Web scraping itself is not a security threat. However, malicious actors may misuse scraping techniques for harmful activities such as data breaches or spamming. Responsible web scraping practices prioritize data privacy and security.
Web scraping always causes harm to websites.
Fact: While excessive and aggressive scraping can lead to increased server load and slower page loading times, not all scraping activities are detrimental to websites. Responsible scraping involves setting reasonable request frequencies and respecting website resources.
Web scraping is only used for competitive advantage.
Fact: Web scraping has a wide range of applications beyond competitive advantage. It is used for data analysis, market research, content aggregation, sentiment analysis, and various other purposes that can benefit individuals, businesses, and researchers.
Web scraping is hard to learn.
Fact: Web scraping is accessible to beginners. There are many resources online. Feel free to reach out to me for guidance and resources to get started.
A Simple Web Scraping Program With Python
This program prints all the links and text found on the Twitter website.
Installing required libraries
pip install requests
pip install bs4Main Program
import requests
from bs4 import BeautifulSoup
# Make a request to the target website (Twitter)
response = requests.get("https://www.twitter.com/")
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Find specific elements on the page using CSS selectors
# Here's an example of finding all <a> tags (links) on the page
links = soup.find_all("a")
# Print the text and URLs of the found links
for link in links:
link_text = link.text
link_url = link["href"]
print(f"Link Text: {link_text}")
print(f"Link URL: {link_url}")
else:
print("Request was not successful.")
More information about setting up the above program visit this link
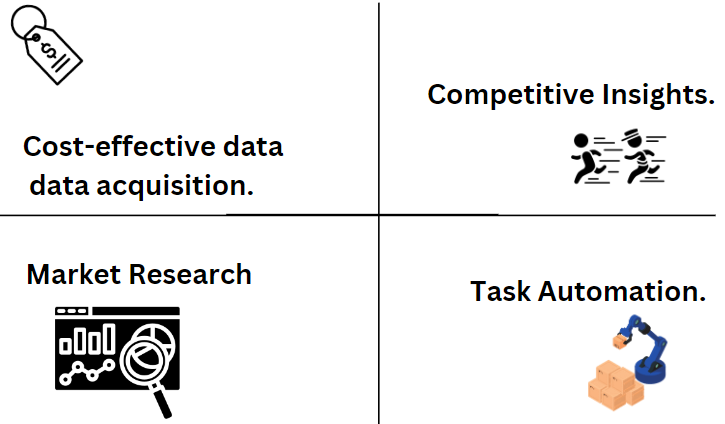
Advantages of Web Scraping for Businesses and Startups
- Cost-effective data acquisition: Web scraping saves costs by automating data gathering instead of manual entry or costly data providers.
- Competitive insights: Scraping competitor websites provides valuable information on strategies, pricing, and products for staying ahead.
- Market research: Web scraping helps understand market trends and consumer preferences for informed decision-making.
- Task automation: Automating repetitive tasks through web scraping enhances efficiency and allows for strategic focus.
In general,
Web scraping is a legal and powerful tool for data gathering and insights.
- It can be compared to taking everyday photos with your phone, generally allowed.
- However, scraping protected or confidential information is illegal, similar to photographing restricted areass
- If you require data from a website but there are no available APIs or they are prohibitively expensive, consider leveraging web scraping as a cost-effective solution. It enables you to access the desired information and empowers you with valuable insights, ensuring informed decision-making without breaking the bank. Embrace web scraping responsibly as a powerful tool in your data acquisition toolkit.
More about legality of Web Scraping? Then, Read a free Ebook from Amber Zamora....