Introduction of Neural Networks for Advanced Deep Learning (Part 3).


Getting our hands dirty with code, so now we will train a neural network to understand the handwritten digits.
let us get our hands dirty so now we will be making our first neural network and make it to test the result of our trained brain.
here we will be working to create a neural network for a handwritten digit recognizer using the MNIST dataset.
MNIST (Modified National Institute of Standards and Technology) is a widely used dataset in machine learning and computer vision.
It consists of 70,000 grayscale images of handwritten digits (0 to 9), each of size 28x28 pixels. The dataset is commonly used for training and evaluating image classification algorithms. MNIST has played a pivotal role in benchmarking and comparing the performance of various models in the field. It serves as an introductory dataset for beginners to practice and understand image recognition tasks.
To train this we will work on the same mode and use the same architecture as applied in the previous articles. When the model will be trained and ready we will test it for prediction, the goal is to create a network to predict digits from 0-9.
Below will be the architecture of our neural network.
MNIST has images in 28x28 pixels shape, so we will have 784 input layers. and the output will have 10 digits. In the hidden layer, the architecture will have other three hidden layers. [ 784, 128, 64, 32 10]. activation function Relu will be the activation function for the hidden layer and softmax will be the activation function for the output layer this is because it is the classification problem.

LIBRARIES:
NumPy: This is a powerful Python library that makes working with arrays and mathematical operations easy, allowing you to perform numerical computations efficiently.
Matplotlib: Also this is a popular Python library that enables you to create high-quality visualizations, such as charts and graphs, from data in a simple and straightforward manner.
PIL (Python Imaging Library) or sometimes Pillow: PIL is a Python library used for opening, manipulating, and saving image files, making it convenient to work with images and perform various image processing tasks. The pillow is a modern fork of PIL, providing more functionalities and ongoing support.

Weights and biases.
In machine learning, weights represent the strengths of connections between neurons in a neural network and determine how much influence each input has on the final output.
Biases are like the "base values" that neural network neurons start with, allowing them to adjust the importance of inputs and help the model better fit the data.
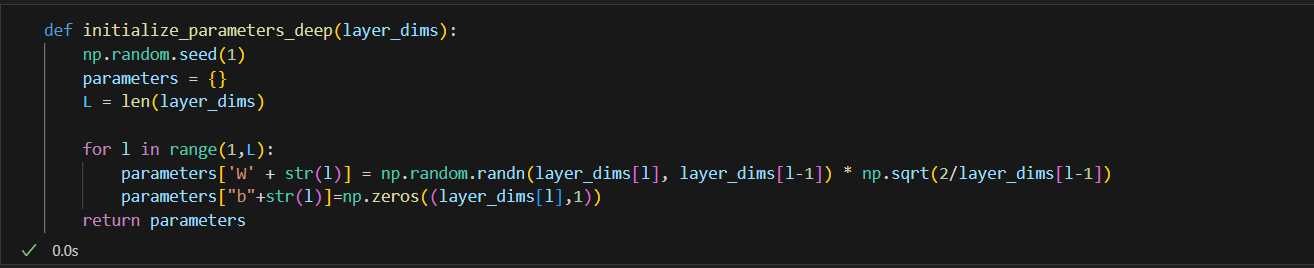
Activation function.
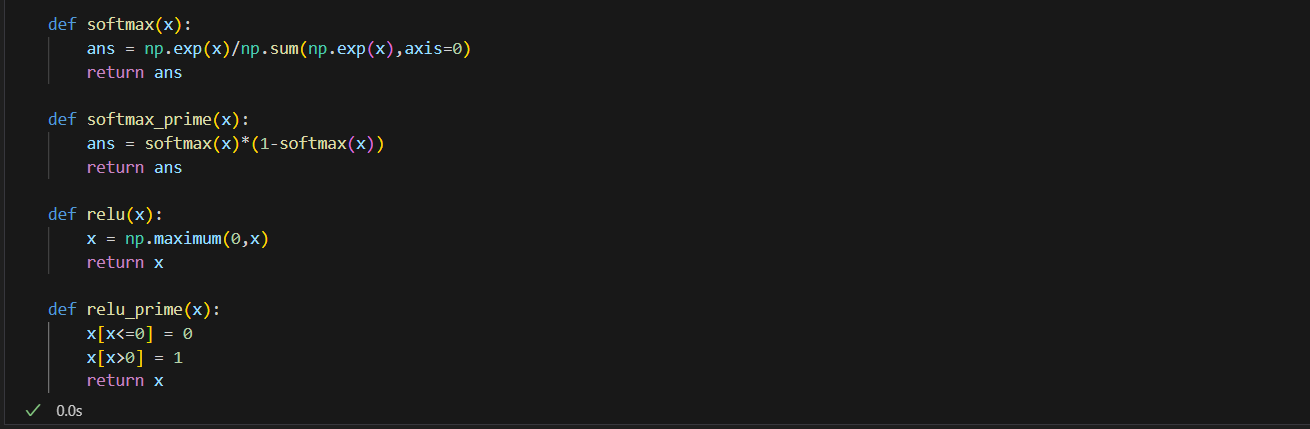
The function used here is Relu and Softmax:
ReLU (Rectified Linear Unit):
ReLU is a simple activation function used in neural networks, which outputs the input value if positive and zero otherwise, effectively introducing non-linearity to the model and helping it learn complex patterns.
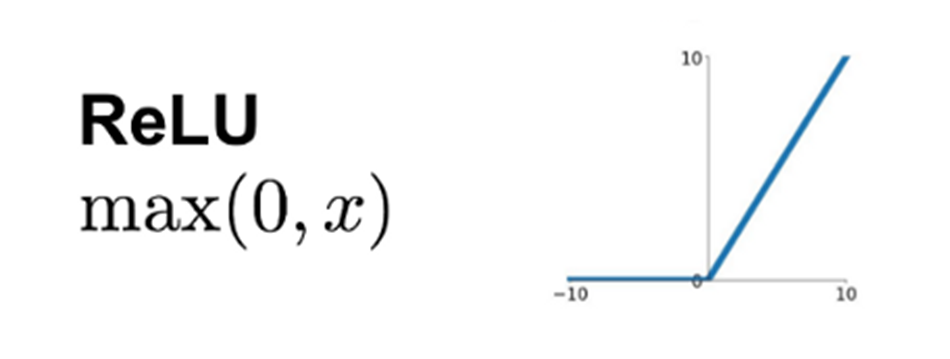
Softmax:
Softmax is an activation function that converts a set of numbers into probabilities, making the largest number the most likely and the smallest the least likely, commonly used in the output layer of a multi-class classification neural network.
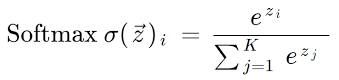
In the code implementation they are here:
FORWARD PROPAGATION:
Here is also the process in a neural network where input data is fed through the model, layer by layer, to compute and output predictions or activations for the next layer. In this part, we will have three functions, linear_forward, deep_layer, and forward_pass.
Linear_Forward:

Deep_layer:
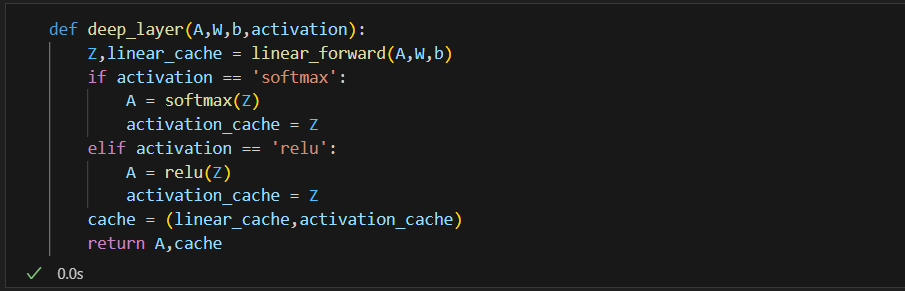
Forward_pass:
LOSS_FUNCTION:
The function to calculate costs is as below:

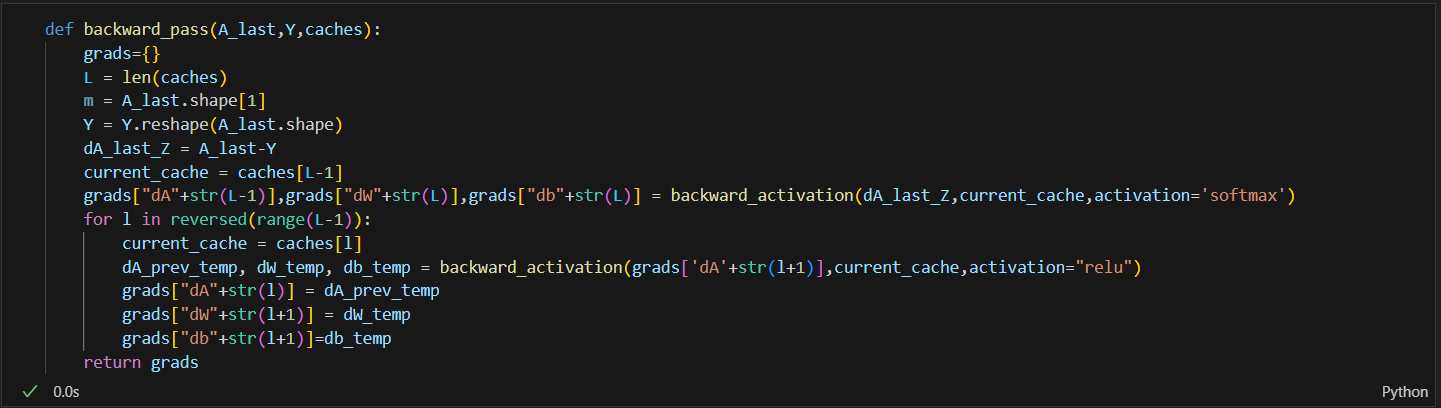
BACKWARD PROPAGATION:
Backward propagation is a method used in neural networks where the model adjusts its internal parameters based on the prediction errors to improve its accuracy during training.
In this part here we also had three equations as well:
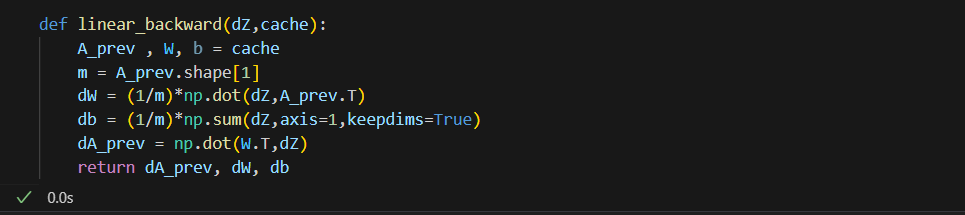
Linear_Backward:
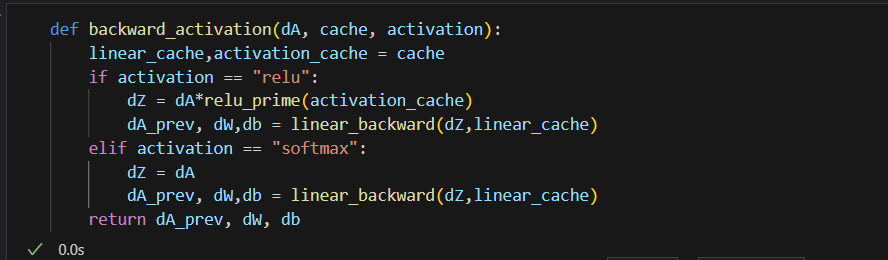
Backward_Activation:
Backward_pass:
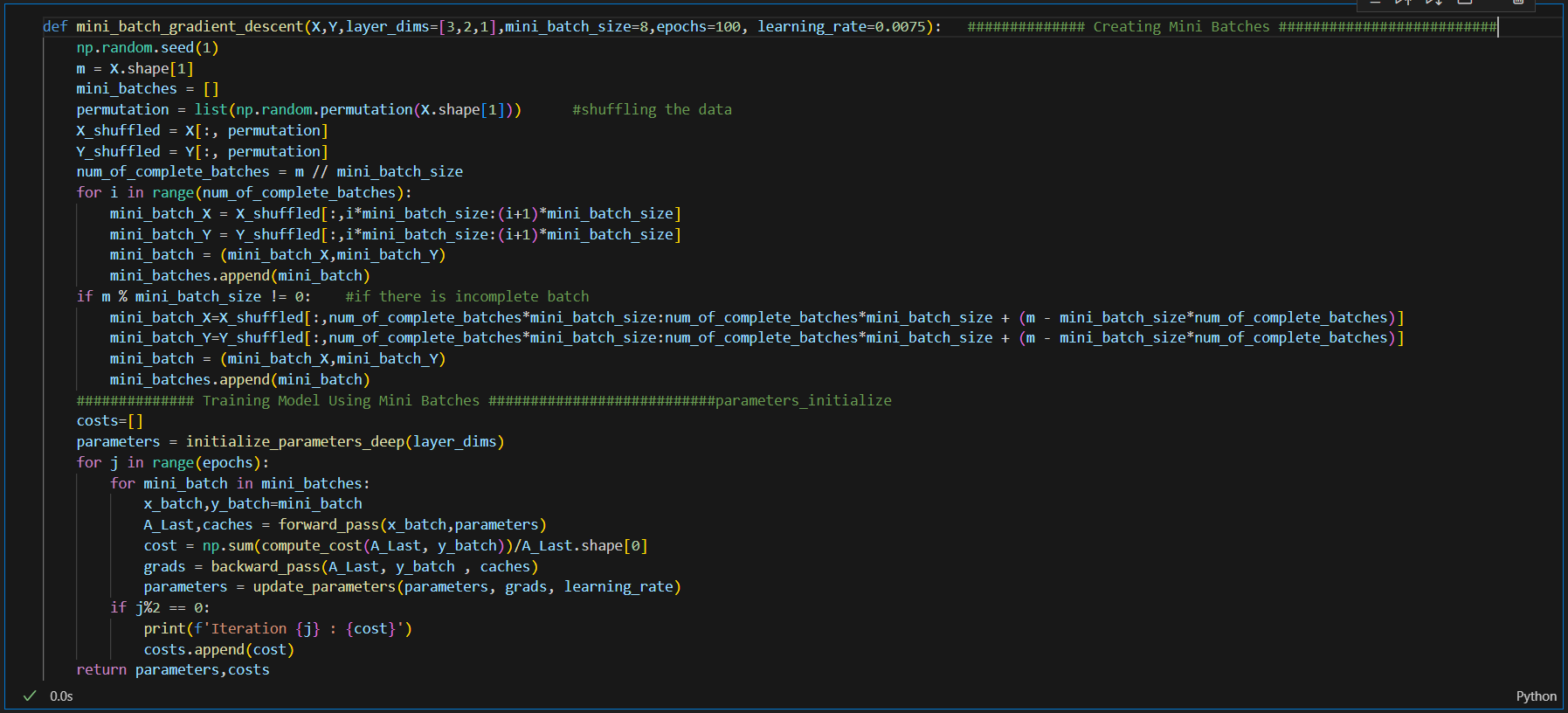
IMPLEMENTING MINI-BATCH

GRADIENT(Model Compiling):
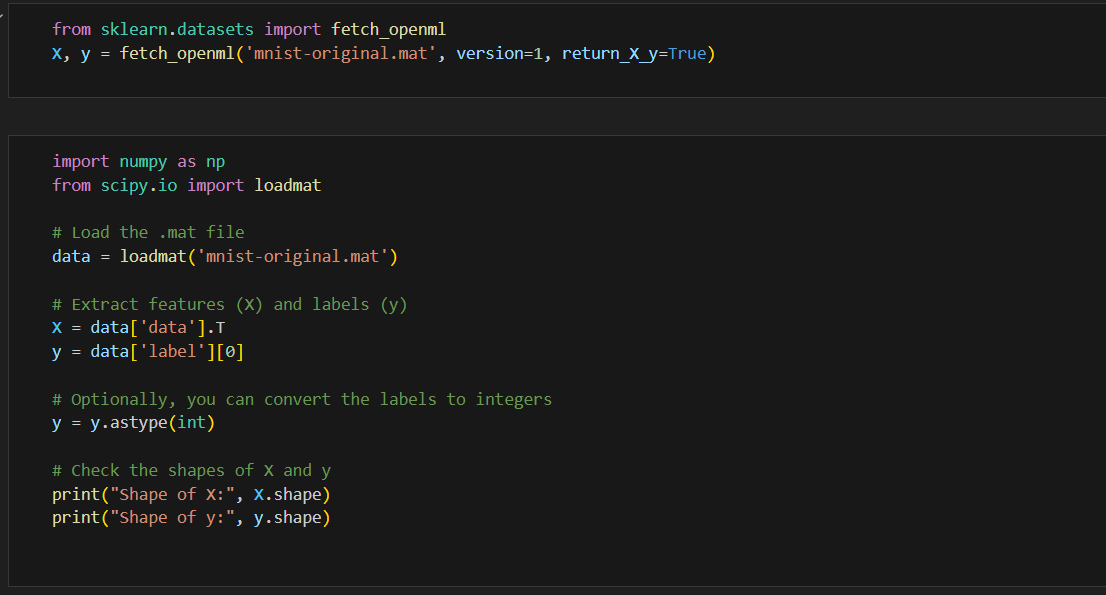
DATASET LOAD AND PREPROCESSING:
The MNIST dataset was downloaded using this link HERE.
In the code below we will import the sklearn library then data load, then we will use the one-hot encoding function to convert the output into one hot vector.
The one-hot encoding will be applied as below (This is a technique used to represent categorical data, where each category is converted into a binary vector with one element set to 1 and all others set to 0, indicating the presence or absence of that category. ):
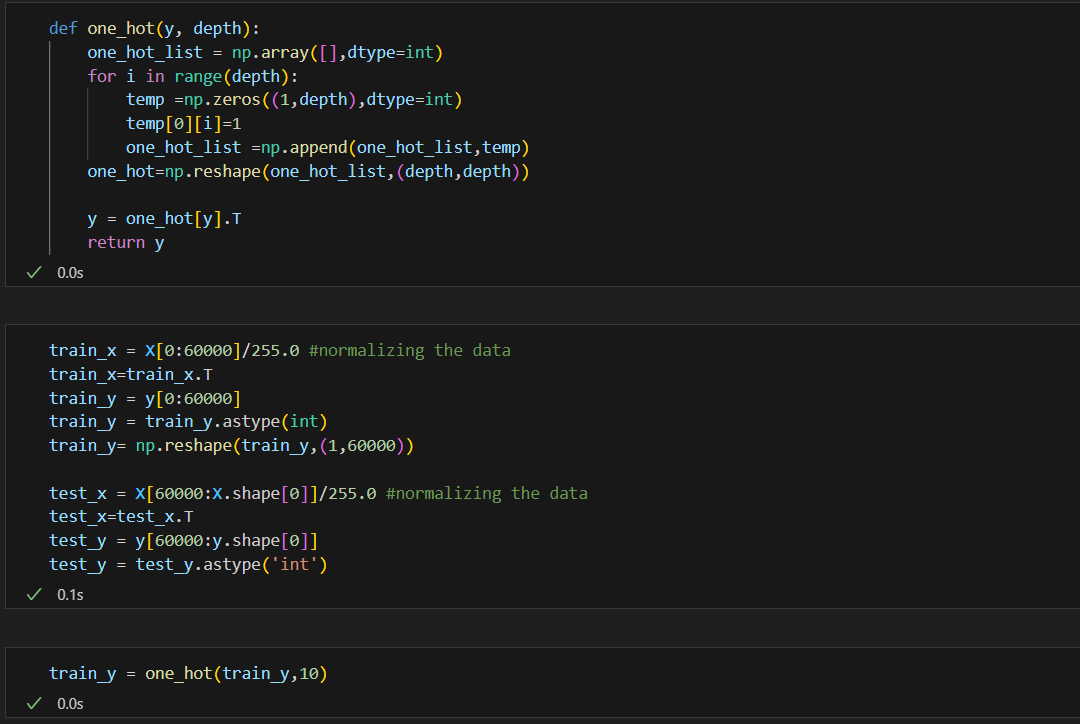
mini batch normalization for parameters;

RUN THE MODEL:
To test the model the code below was used to test it by passing test_x through the forward pass and predict the result. the accuracy of the results was found to be 97.10%
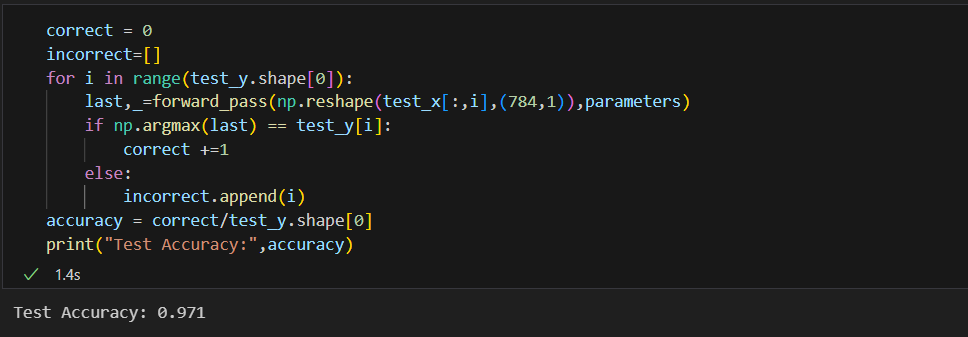
TESTING THE MODEL:
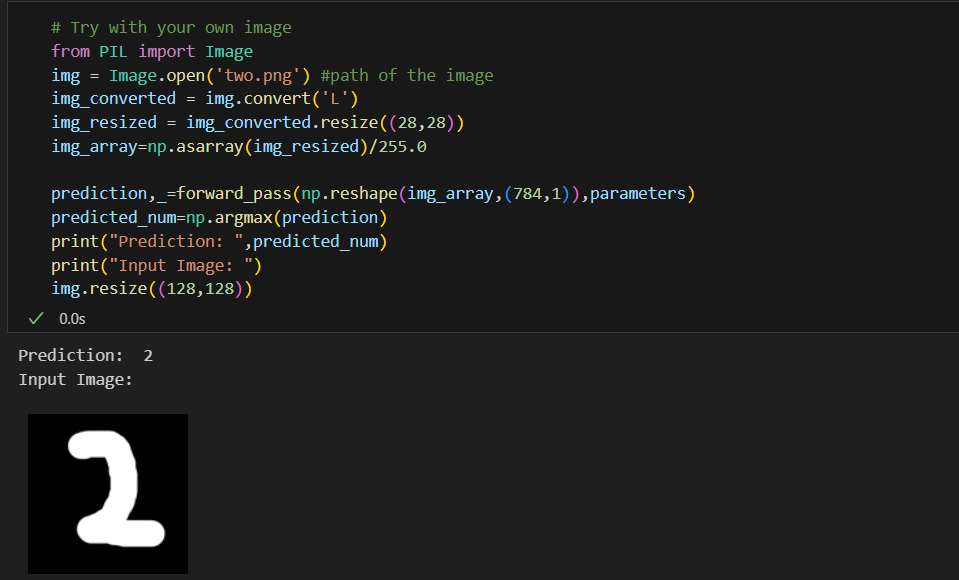
the model will be tested by trying on our own images. for more accuracy it is advised that images have black backgrounds and white digits as will be given in the sample code, this happens because we use the same kind of images. if inverted the network may fail. To try your own images just try changing the name of the images in the images name path.
The whole source code can be found HERE.
If you may find any issues feel free to report them through GitHub issues HERE.
After all the explanation here let us have a chat conversation for those who will try this out: Mgasa Lucas