Intro To LLMs
Welcome to the introduction series on LLM.

Have you ever wondered what LLMs are and why they are so popular? You are not alone. Many people have heard of LLMs, but few actually know what they entail, how they benefit, or how to pursue them. In fact, there is a humorous post on LinkedIn that captures this confusion perfectly:
LLMs are like trendy diets, everyone talks about them, no one really knows how to do them, everyone thinks everyone else is doing them, so everyone claims they are doing them.
Unlike trendy diets, LLMs are not a passing trend. They are a prestigious and worthwhile academic degree that can boost your skills and career prospects. In this article, I will give you a brief introduction to LLMs, and explain what they are, why they are popular, how they work and how to actually use them.
INTRODUCTION
Large Language Models (LLMs) are advanced artificial intelligence (AI) systems that can understand and generate human-like language. They can perform various language tasks, such as answering questions, summarising text, translating languages, and even composing poetry. LLMs have revolutionised the field of natural language processing (NLP) and opened up new possibilities for various industries and applications. In this article, we will explore what LLMs are, how they work, what they can do, and what challenges and limitations they face.
A Language Model (LLM) basically comprises two essential files within a designated hypothetical directory. One file holds the parameters, known as the parameter file, while the other is the executable file responsible for running the parameters of the Neural Network constituting the language model.
For illustration purposes in this article, we will focus on a specific LLaMa 2 series model – the llama-2-70b model. This particular model has 70 billion parameters, all thoroughly trained on a substantial portion of text sourced from the internet.
The parameters themselves represent the weights of the Neural Network. In the case of the llama-2-70b model, an open-source model from Meta, each parameter is stored as 2 bytes, resulting in a parameters file size of 140 GB.
OBTAINING THE PARAMETERS (Model Training)
Running an LLM, specifically model inferencing, is a relatively undemanding task. The computational complexity comes into play when accessing the parameters, particularly during the model training phase.
Obtaining the parameters involves a process similar to condensing or compressing the internet. Textual segments from the internet, along with various document types, undergo compression, forming what can be conceptualised as a zip file of the internet. This can visually witnessed in the image below:

However, it's essential to note that this process isn't a conventional compression; instead, it employs a lossy compression method, distinct from the typical lossless compression.
In contemporary model training, the above numbers numbers may seem modest, as they are understated by a factor of 10 or more. This assertion underscores the justification for the substantial financial investments—amounting to tens and hundreds of dollars—in the training of Language Models (LLMs). This training involves extensive clusters and datasets.
Once the parameters are obtained through the completion of the model training phase, executing the model (model inferencing) becomes a relatively computationally economical task.
NEURAL NETWORKS
Essentially, Language Models (LLMs) operate by predicting the next word in a sequence. Mathematically, it can be demonstrated that there exists a close correlation between prediction and compression. This is the reason why the process of training the Neural Network (NN) is often likened to compressing the internet. The NN becomes skilled at accurately predicting the next word by leveraging the insights derived from the compressed dataset.
Although the concept of predicting the next word may sound straightforward in the preceding passages, it is, in reality, a strong objective. This objective forces the Neural Net to acquire a wealth of knowledge about the world within the parameters of the Neural Network.
To illustrate, consider a random Wikipedia search:
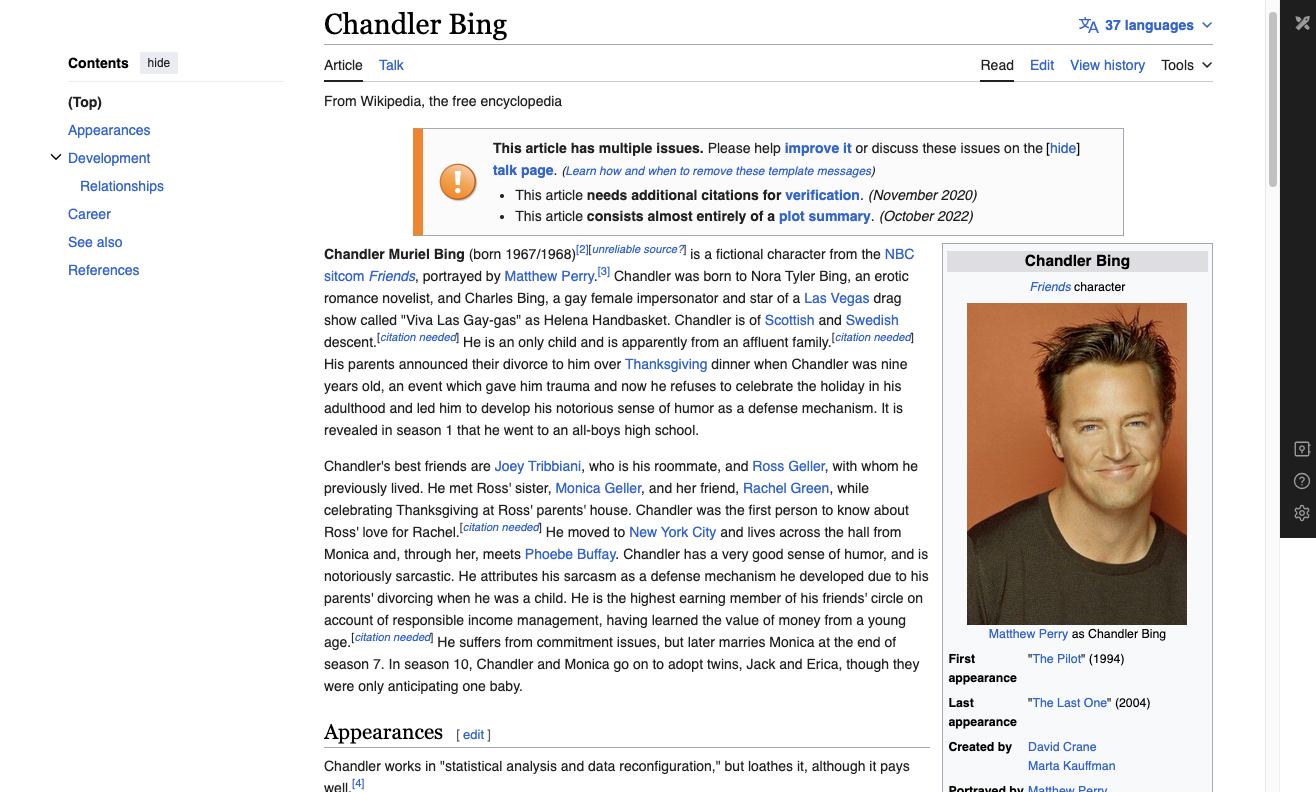
Now put yourself in the shoes of the Neural Net attempting to predict the next word, you'd encounter words loaded with information, many of them highlighted in blue. Given the task of predicting the next word, the parameters must grasp a lot of knowledge such as the first and last name, birthplace of Chandler, his friendships, whether he is a fictional character, his residence, nationality, occupation, and more. Consequently, in the pursuit of next-word prediction, all the acquired knowledge is condensed or compressed and stored within the parameters.
HOW DO WE ACTUALLY USE THE NEURAL NETS?
When we execute a Neural Network or a Language model, what we receive is akin to a web page dream or hallucination. The neural network essentially "dreams" the content of internet documents.
The NN generates texts from the distribution it was trained on, essentially mimicking these documents. In essence, it engages in a form of hallucination based on the lossy compression applied during the model training phase.
Let's explore a couple of examples to illustrate this process. Consider the generation of ISBNs: the number produced may not exist in reality, but it is generated based on the Neural Net's understanding that after the word "ISBN" comes a number of a certain length and with specific digits. The NN then fabricates a number that aligns with these criteria.
Another example involves prompting the model to discuss a specific animal, like a koala bear. The Neural Net produces information about the koala bear based on the knowledge embedded in its parameters. This knowledge is acquired through lossy compression during the training phase. However, the model doesn't regurgitate information verbatim from a particular internet source it was trained on.
In the instances mentioned above, we witness the Language model or the Neural Net in its hallucinatory or dream-like state.
HOW THE NEURAL NETWORK WORKS
In this segment of the article, we delve into the mechanics of how the Neural Network or the Language Model accomplishes the task of predicting the next word. This is where things start to get a bit complex.
Here, we zoom in on the diagram of the Neural network, known as the Transformer neural network architecture. A comprehensive understanding involves delving into the mathematical operations and the various stages implicated in the next word prediction task.
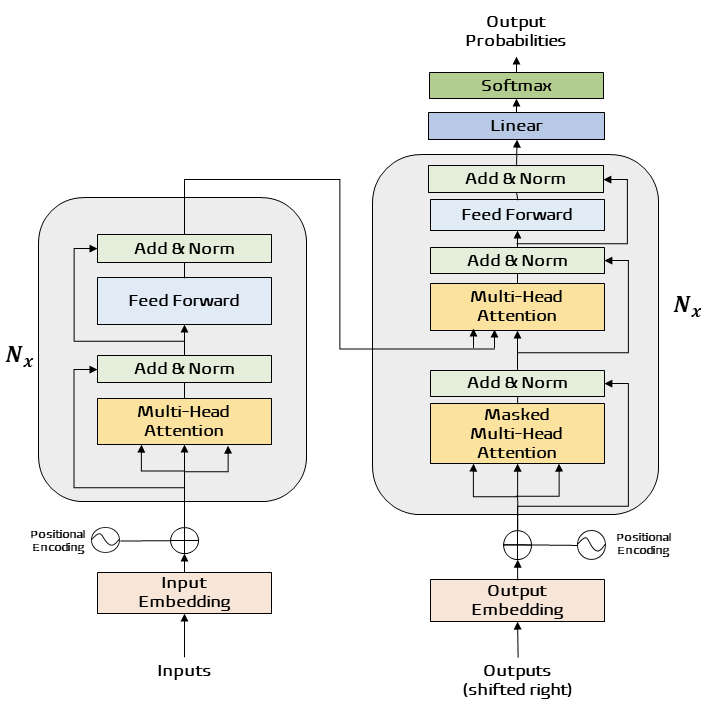
However, full comprehension is elusive, and what we do know in detail is limited:
- There are billions of parameters distributed throughout the neural network.
- We know how to iteratively adjust and fine-tune these parameters to enhance predictive capabilities.
- While we can measure the model's performance and probability, understanding how each of the billions of parameters contributes to this performance remains a challenge.
The neural nets construct a knowledge database, but it remains somewhat perplexing, messy, and imperfect. An example illustrating this is the concept of what is known as "reverse course."
For instance, if you ask ChatGPT about the mother of Tom Cruise, it might correctly respond with Mary Lee Pfeiffer. However, in the same chat, if you inquire about Mary Lee Pfeiffer's son, it might answer with Tom Cruise.

Interestingly, if you pose the question in a separate chat, asking specifically about Mary Lee Pfeiffer's son, you might receive a response indicating a lack of clarity.
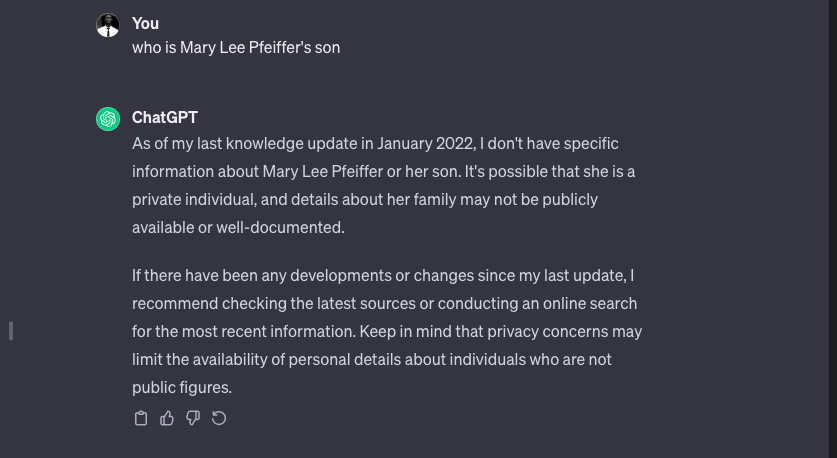
This demonstrates that the knowledge base is somewhat messy and one-dimensional. It cannot be readily accessed in any direction, requiring a specific approach to access information—a phenomenon known as Prompt Engineering.
CONCLUSION
In summary, Language Models (LLMs) should be viewed as largely inscrutable artefacts. They differ significantly from engineered structures like cars, where each part and its function are well-understood. LLMs, being Neural Networks resulting from a lengthy optimisation process, are not currently fully understood. While there is a field known as interpretability or mechanistic interpretability attempting to decipher the functions of various parts of Neural Networks, LLMs are presently treated as empirical artefacts. We can input data, measure output and behavior, and analyse responses in diverse scenarios, but the intricate workings remain a subject of ongoing exploration.