Building a Chatbot from Your Documents with ChatGPT - No Vector Database Required

Introduction
In today's world, businesses are constantly looking for new ways to improve their customer service and engagement. One way to do this is by creating a chatbot that can quickly and accurately answer customer questions. In this article, we will show you how to create a chatbot that is based on your own company documents.
There are a number of ways you could do this, In this article, you're going to explore some of them with their pros and cons, and we will be looking at fine-tuning GPT-3, direct prompt-engineering, and linking vector-index with GPT-3 API.
Fine Tuning GPT-3?
For those who don't know, Fine-tuning a pre-trained machine learning model involves training the model on a smaller dataset specific to a new related task, in order to adapt its already-learned knowledge and improve its performance on the new task.
I initially thought of fine-tuning GPT-3 on my own data. But, fine-tuning can be quite expensive as it is one of the largest and most complex language models with over 175 billion parameters, making it computationally intensive to train plus requiring a sizable dataset with examples.
Also, every time the document is altered, it is impossible to make final adjustments. Perhaps more importantly, fine-tuning teaches the model a new ability rather than merely letting it "know" all the information included in the documents. Consequently, fine-tuning is not the best approach for (multi-)document QA.
How about Prompt Engineering?
Prompt engineering is the art of crafting the initial input text for a language model, such as ChatGPT, during a conversation, to help it understand the context and generate responses that are relevant and meaningful to the user's queries.
I then thought of utilizing this as the second strategy to build a chatbot from documents whereby I can pass my document's text as a context before the question itself instead of asking it directly. Nevertheless, the GPT model has a short attention span and can only process a small number of the prompt's 2,000 words (about 4000 tokens or 3000 words).
Given that we have tens of thousands of emails from customers providing feedback and hundreds of product documentation, it is impossible to convey all the information in the prompt. Because the pricing is based on the number of tokens you use, it is also expensive if you give in a lengthy context to the API.
How about Vector-Index + GPT-3?
Lastly, an idea came up of using a semantic search algorithm to search through the documents, retrieve relevant context, and then pass this along with my questions to the ChatGPT API to counter the issue of a limited number of tokens.
To do this I found a library called llama-index (formerly known as gpt-index) while doing research for my idea that accomplishes exactly what I wanted it to do and is easy to use.
Building Our Chatbot using llama-index + ChatGPT API
Step 1: Prepare Your Company Documents
The first step is to gather all the documents that you want to use to create the chatbot. These documents can include product manuals, FAQs, and other helpful resources that your customers may need to reference. Once you have gathered your documents, you need to organize them into a folder called 'data' and save them in a format that can be easily read by Python.
Step 2: Installing and importing the Required Libraries
To build a chatbot, we need to use some Python libraries that are specifically designed for natural language processing and machine learning. In this code snippet, we are using the llama_index and langchain. You can install these libraries using pip:
$ pip install llama_index
$ pip install langchain
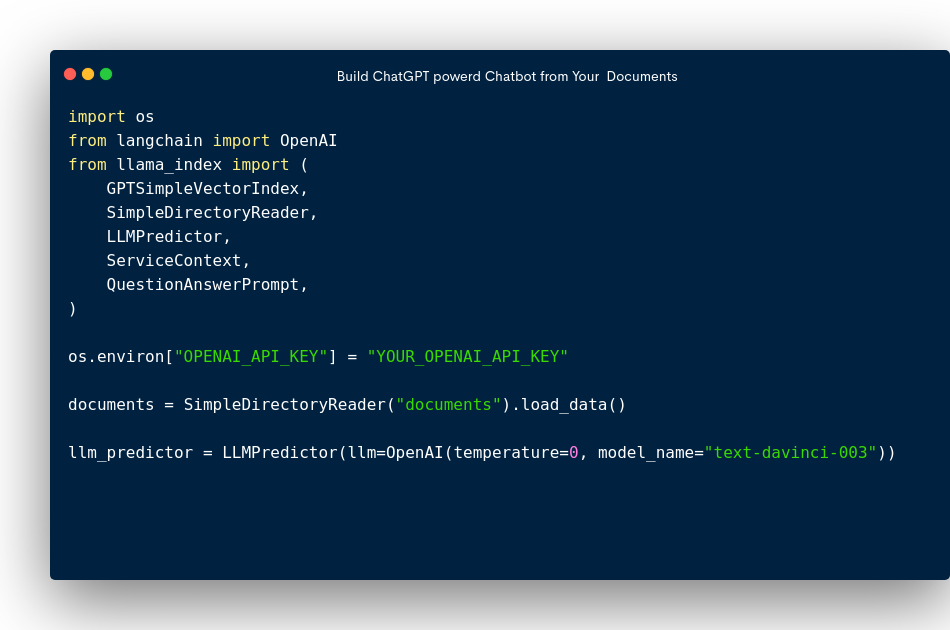
After a successful installation, the libraries are then imported:
import os
from langchain import OpenAI
from llama_index import (
GPTSimpleVectorIndex,
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
QuestionAnswerPrompt,
)
Step 3: Set Up OpenAI API Key
To use the OpenAI language model, we need to set up our API key. You can get your own API key by signing up on the OpenAI website. Once you have your API key, replace 'YOUR_OPENAI_API_KEY' with your actual key in the following code line:
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
Step 4: Load Your Company Documents
In this code snippet, we are using the SimpleDirectoryReader class from the llama_index library to load our company documents from the 'documents' folder:
documents = SimpleDirectoryReader('documents').load_data()
Step 5: Set Up the Language Model
Next, we need to set up the language model that we will use to analyze the text in our company documents. In this code snippet, we are using the text-davinci-003 model from OpenAI and setting the temperature to 0 to ensure that the responses are always the same:
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
Step 6: Set Up the Service Context and Index
We are using the ServiceContext class to define the parameters for the chatbot service. Then, we create the GPTSimpleVectorIndex class from our company documents and the service context to build an index of our documents:
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
Step 7: Save and Load the Index
We save our index to a file called 'index.json' so that we can reuse it later:
index.save_to_disk('index.json')
We can then load the index from the file using the load_from_disk method:
index = GPTSimpleVectorIndex.load_from_disk('index.json')
Step 8: Set Up the Question-Answer Prompt
In this code snippet, we create a QuestionAnswerPrompt class and define a template for the chatbot's responses. The template includes the context information and a query string that the user can input to ask a question, this may be optional but it helps the chatbot with further instructions on how to answer some questions:
QA_PROMPT_TMPL = (
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
Step 9: Test the Chatbot
Finally, Let's organize all our snippets into our place and then test our chatbot by inputting a sample query string and printing the response:
import os
from langchain import OpenAI
from llama_index import (
GPTSimpleVectorIndex,
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
QuestionAnswerPrompt,
)
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
documents = SimpleDirectoryReader("documents").load_data()
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
index.save_to_disk("index.json")
index = GPTSimpleVectorIndex.load_from_disk("index.json")
QA_PROMPT_TMPL = (
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
query_str = "What is the mission of the company?"
response = index.query(query_str, text_qa_template=QA_PROMPT)
print(response)
The chatbot will analyze the query string and search through our company documents to find the most relevant answer. It will then provide a response based on the template that we defined in Step 8.
Conclusion
In this article, we have shown you how to create a chatbot that is based on your own company documents using Python and some powerful AI tools. With this chatbot, you can provide your customers with quick and accurate answers to their questions, improving your customer service and engagement. By customizing the chatbot's responses based on your company's unique resources, you can create a chatbot that is tailored to your specific needs.