Get started with topic modeling using GENSIM.
This is interactive article designed to give reader a clear practical understanding on how to implement Gensim for Topic modelling in NLP.


INTRODUCTION
As one application of NLP Topic modeling is being used in many business areas to easily scan a series of documents, find groups of words (Topics) within them, and automatically cluster word groupings, this has saved time and reduced costs.
In this article, you're going to learn how to implement topic modeling with Gensim, hope you will enjoy it, let's get started.
Have you ever wondered how hard is to process 100000 documents that contain 1000 words in each document? , that means it takes 100000 * 1000 =100000000 threads to process all documents. This can be hard, time, and memory-consuming if done manually, that's where Topic modeling comes into play as it allows to programmatically achieve all of that, and that's what you're going to learn in this article
WHAT IS TOPIC MODELLING?
Topic Modelling can be easily defined as the statistical and unsupervised classification method that involves different techniques such as Latent Dirichlet Allocation (LDA) topic model to easily discover the topics and also recognize the words in those topics present in the documents. This saves time and provides an efficient way to understand the documents easily based on the topics.
Topic modeling has many applications ranging from sentimental analysis to recommendation systems. consider the below diagram for other applications.
Now that you have a clear understanding of what the topic modeling means, Let's see how to achieve it with Gensim, But wait someone there asked what is Gensim?
WHAT IS GENSIM?
Well, Gensim is a short form for the generate similarity that is Gen from generate and sim from similarity, it is an open-source fully specialized python library written by Radim Rehurek to represent documents vectors as efficiently(computer-wise) and painlessly(human-wise) as possible.
Genism is designed to be used in Topic modeling tasks to extract semantic topics from documents, Genism is your tool in case you're want to process large chunks of textual data, it uses algorithms like Word2Vec, FastText, Latent Semantic Indexing (LSI, LSA, LsiModel), Latent Dirichlet Allocation (LDA, LdaModel) internally.

WHY GENSIM?
1. It has efficient, implementations for various vector space algorithms as mentioned above.
2. It also provides similarity queries for documents in their semantic representation.
3. It provides I/O wrappers and converters around several popular data formats.
4. Gensim is so fast, because of its design of data access and implementation of numerical processing.
HOW TO USE GENSIM FOR TOPIC MODELLING IN NLP.
We have come to the meat of our article, so grab a cup of coffee, fun playlists from your computer with Jupyter Notebook opened ready for hands-on. let's start.
In this section, we'll see the practical implementation of the Gensim for Topic Modelling using the Latent Dirichlet Allocation (LDA) Topic model,
Installation
Here we have to install the gensim library in a jupyter notebook to be able to use it in our project, consider the code below;
! pip install --upgrade gensimLoading the datasets and importing important libraries
We are going to use an open-source dataset containing the news of millions of headlines sourced from the reputable Australian news source ABC (Australian Broadcasting Corporation)Agency Site: (ABC).
The datasets contain two columns that are publish_date and headlines_texts column with millions of the headlines.
Consider the below code for importing the required libraries.
#importing library
import pandas as pd #loading dataframe
import numpy as np #for mathematical calculations
import matplotlib.pyplot as plt #visualization
import seaborn as sns #visualization
import zipfile #for extracting the zip file datasets
import gensim #library for topic modelling
from gensim.models import LdaMulticore
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
import nltk #natural language toolkit for preprocessing the text data
from nltk.stem import WordNetLemmatizer #used to Lemmatize using WordNet's #built-in morphy function.Returns the input word unchanged if it cannot #be found in WordNet.
from nltk.stem import SnowballStemmer #used for stemming in NLP
from nltk.stem.porter import * #porter stemming
from wordcloud import WordCloud #visualization techniques for #frequently repeated texts
nltk.download('wordnet') #database of words in more than 200 #languages
Now, we have managed to install Gensim and import the supporting libraries into our working environment, consider the below codes for installation of the other libraries if not installed yet in your jupyter notebook,
! pip install nltk #installing nltk library
! pip install wordcloud #installing wordcloud libraryAfter successful importing the above libraries, let's now extract the zip datasets into a folder named data_for_Topic_modelling as shown on the below codes;
#Extracting the Datasets
with zipfile.ZipFile("./abcnews-date-text.csv.zip") as file_zip:
file_zip.extractall("./data_for_Topic_modelling")Nice, we have successfully unzipped the data from zip file libraries that we imported above, remember? , Now let's load the data into a variable called data, since the datasets have more than millions of news for this tutorial we are going to use 500000 rows using slicing techniques in python language of the headline news from ABC.
consider the code below for doing that;
#loading the data
#Here we have taken 500,000 rows of out dataset for implementation
data=pd.read_csv("./data_for_Topic_modelling/abcnews-date-text.csv")
data=data[:500000] #500000 rows taken EDA and processing the data
Nice, after having the data on our variable named data as above shown from code, we have to check how it looks like hence EDA means exploratory data analysis and hence we will do some processing the data to make sure we have dataset ready for the algorithm to be trained,
Here in the code below, we have used the .head() function that prints the first five rows from the datasets, this helps us to know the structure of the data and hence confirmed it is of texts.
#Checking the first columns
data.head()
Here we try to check the shape of the dimension of the dataset and hence confirmed we have the rows that we selected at the start of loading the data, hence, pretty ready to go.
#checking the shape
#as you see there are 500000 the headline news as the rows we selected above.
data.shape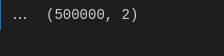
Now, we have to delete the publish_date column from the dataset using the keyword del as shown below codes, why? because we don't want it our main focus is to model the topics according to the document that has a lot of headline news, so we consider the headline _text column.
#Deleting the publish data column since we want only headline_text #columns.
del data['publish_date']
#confirm deleteion
data.head()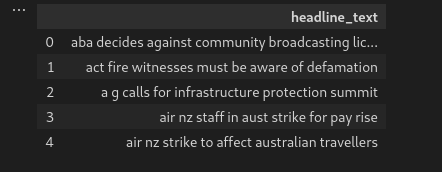
Now we have remained with our important column which is headline_text as seen above, and here we now using wordcloud to get a look at the most frequently appearing words from our datasets in headline_text columns, this increase more understanding about the datasets, consider the code below
#word cloud visualization for the headline_text
wc = WordCloud(
background_color='black',
max_words = 100,
random_state = 42,
max_font_size=110
)
wc.generate(' '.join(data['headline_text']))
plt.figure(figsize=(50,7))
plt.imshow(wc)
plt.show()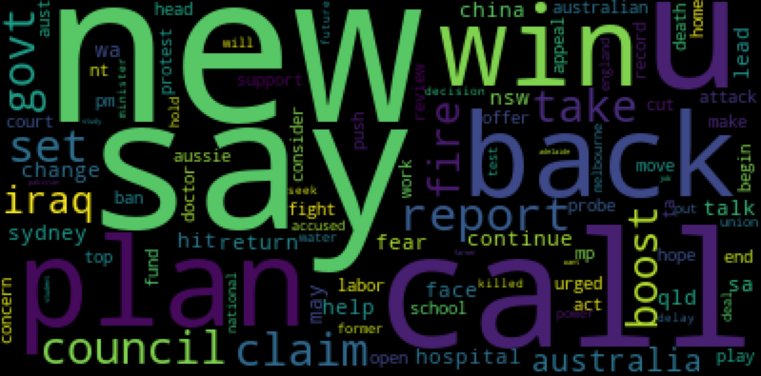
Hereafter visualizing the data, we process the data by starting with stemming, which is simply the process of reducing a word to its word stem that is to say affixes to suffixes and prefixes or to the roots of words known as a lemma . Example cared to care. Here we are using the snowballStemmer algorithm that we imported from nltk, remember right?
consider the below code function code;
#function to perform the pre processing steps on the dataset
#stemming
stemmer = SnowballStemmer("english")
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))Then continue to tokenize and lemmatize, where here we split the large texts in headline text into a list of smaller words that we call tokenization, and finally append the lemmatized word from the lemmatize_stemming function above code to the result list as shown below;
# Tokenize and lemmatize
def preprocess(text):
result=[]
for token in gensim.utils.simple_preprocess(text) :
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
#Apply lemmatize_stemming on the token, then add to the results list
result.append(lemmatize_stemming(token))
return resultThen after the above steps, here we just call the preprocess() function
#calling the preprocess function above
processed_docs = data['headline_text'].map(preprocess)
processed_docs[:10]
Create a dictionary from 'processed_docs' from gensim.corpora containing the number of times a word appears in the training set, and call it a name it a dictionary, consider below code
dictionary = gensim.corpora.Dictionary(processed_docs)Then, after having a dictionary from the above code, we have to implement bags of words model (BoW), BoW is nothing but a representation of the text that shows the occurrence of the words that are within the specified documents, this keeps the word count only and discard another thing like order or structure of the document, Therefore we will create a sample document called document_num and assigned a value of 4310.
Note: you can just create any sample document of your own,
#Create the Bag-of-words(BoW) model for each document
document_num = 4310
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
Checking Bag of Words corpus for our sample document that is (token_id, token_count)
bow_corpus[document_num]
Modeling using LDA (Latent Dirichlet Allocation) from bags of words above
We have come to the final part of using LDA which is LdaMulticore for fast processing and performance of the model from Gensim to create our first topic model and save it
#Modelling part
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics=10,
id2word = dictionary,
passes = 2,
workers=2)For each topic, we will explore the words occurring in that topic and their relative weight
#Here it should give you a ten topics as example shown below image
for idx, topic in lda_model.print_topics(-1):
print("Topic: {} \nWords: {}".format(idx, topic))
print("\n")
Let's finish with performance evaluation, by checking which topics the test document that we created earlier belongs to, using LDA bags of word model, consider the code below
# Our test document is document number 4310
for index, score in sorted(lda_model[bow_corpus[document_num]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic: {}".format(score, lda_model.print_topic(index, 10)))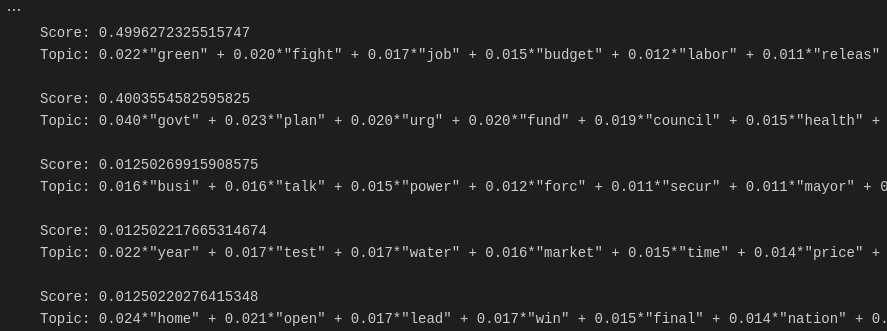
Congrats! if you have managed to reach the end of this article, as you see above we have implemented a successful model using LDA from the Gensim library using bags of the words to easily model the topics present in the documents with 500,000 headline news. The full codes and datasets used can be found here
Relationship Between Neurotech and Natural Language Processing(NLP)
Natural Language Processing is a powerful tool when your solve business challenges, associating with the digital transformation of companies and startups. Sarufi and Neurotech offer high-standard solutions concerning conversational AI(chatbots). Improve your business experience today with NLP solutions from experienced technical expertise.
Hope you find this article useful, sharing is caring.