How Machine Learning Is Revolutionizing Heart Stroke Detection


Did you know that Heart Stroke is the second leading cause of death and the third leading cause of disability worldwide? That's a staggering statistic! But fear not, my friends, because in this thrilling adventure, we're going to explore how AI and Machine learning are changing the game and helping us save lives faster than ever before.
So, what exactly is a heart stroke?
Heart stroke, also known as a cerebrovascular accident (CVA), is a severe medical condition that occurs when the blood supply to the brain is interrupted or reduced, depriving brain cells of oxygen and nutrients. And guess what happens when brain cells are starved of blood? They die! Talk about a life-or-death situation.
That's why it's very important to act FAST and get treatment as soon as possible. Timely identification and prompt treatment are crucial to minimize the potentially devastating effects of a stroke.
Now, before you start yawning at the thought of a medical lecture, let me assure you that this journey is going to be exciting. We're diving into the nitty-gritty details of heart strokes, and I promise you'll be on the edge of your seat!
The Role of Machine Learning.
- Machine learning models have the potential to analyze large datasets and identify patterns that humans might miss.
- By leveraging this technology, we can develop reliable predictive models to assess the likelihood of an individual experiencing a stroke.
- This empowers healthcare professionals to take proactive measures and provide personalized care to those at high risk.

The exciting part is that we don't have to be professional doctors or nurses to make a difference. The world of AI and Machine learning is here to save the day!
AN END-TO-END PROJECT USING MACHINE LEARNING TO DETECT HEART STROKE.
Now, let's get to the heart of the matter: an end-to-end project using machine learning to detect heart strokes. Get ready for a treat because we'll cover everything from business understanding to deployment. It's going to be an exhilarating ride!
The objective of the Project
The objective of this project is to develop a predictive model that can accurately identify individuals who are at risk of experiencing a heart stroke.
We aim to empower Healthcare professionals by leveraging the power of machine learning algorithms and analyzing relevant medical data, to create a predictive model that could assist in early detection and intervention for individuals at risk of experiencing a heart stroke.
Dataset Used
I used an Online Kaggle dataset that can be found here
- The dataset consisted of several features like Age, BMI, Smoking Status, Age, etc.
- The target column is the Stroke column which has two possible values 1 or 0.
- The biggest challenge about this dataset/project is the huge crazy imbalance in the target column. More than 95% of the patients in this dataset had no stroke.
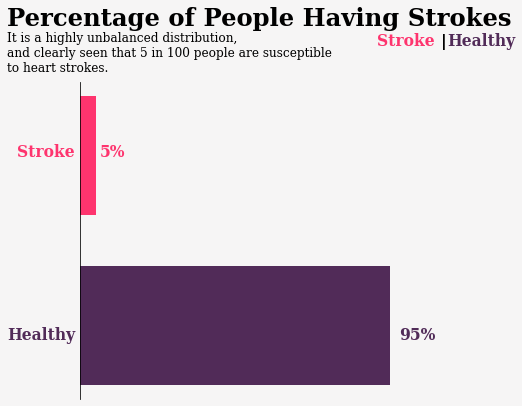
- This means that our data is biased & knows about one side of the data. I will show you some techniques to solve the imbalance of the target.
Now, let's take a closer look at some intriguing insights.
Did you know that age plays a significant role in heart strokes?
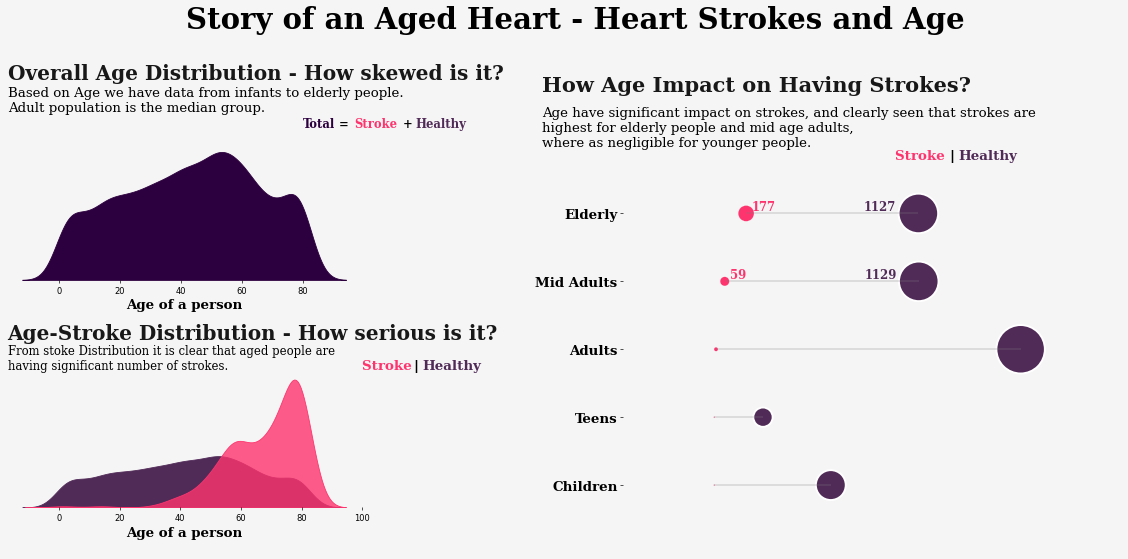
The older people get, the more prone they are to experiencing this medical emergency. This doesn't come as a surprise because hypertension, or high blood pressure, becomes more common as people age. Elevated blood pressure can strain the arteries and weaken their walls, making them more susceptible to rupture or blockage.
In fact, the stats show us that the chance of having a stroke about doubles every 10 years after age 55 which is really scary.
Addressing Class Imbalance
This is the single MOST important thing for this classification task and without it everything else becomes irrelevant. The challenge of working with imbalanced datasets is that most machine learning techniques will ignore, and in turn have poor performance on, the minority class, although typically it is the performance on the minority class that is most important.
The best way to handle class imbalance in a dataset is to use SMOTE which stands for Synthetic Minority Oversampling Technique and it aims to balance class distribution by randomly increasing minority class examples by replicating them.
SMOTE is done exclusively only on the Train data in order to prevent data leakage.
Properly doing the SMOTE is at the core of creating reliable models that can detect Stroke in patients.
You can see in the below image how I balanced the Train data. The left-hand side shows how the stroke status is very imbalanced, but then I did SMOTE which balanced the data shown by the image on the right-hand side.
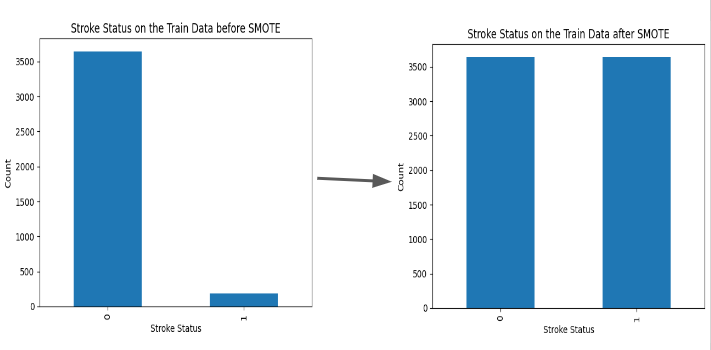
Nothing is done on the test data. Its still clearly imbalanced as shown below.
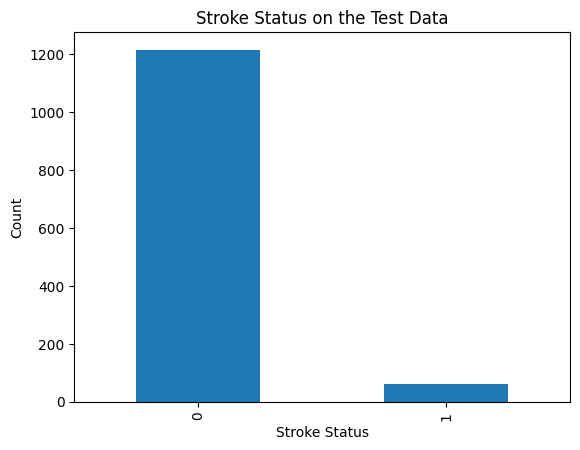
We don't do anything on the test data so as to prevent any sort of data leakage.
Before we can go to any modeling, let's understand how we shall evaluate our models and pick the best one.
Context on How We Shall Identify The Best Model.
- In order to find the best model that will give us the best results, we need to know how much our model predicts people with stroke & how it predicts people with no stroke.
- And to do this, we need to minimize two errors in our data;
- False Negative: These are people who actually have a stroke, but our model predicts them not to have it. This is a very costly mistake as it can lead to big health problems/death for our patients/customers. We need to minimize this as best as we can. A metric called recall will help us to keep track of this
- False Positives: These are people who don’t have a stroke, but our model predicts them to have it. This might mean extra costs for our patient, but we are OK with it. A metric called precision will help us to keep track of this
We are putting our focus on making sure we detect any signs of Stroke and because of this Recall is the most important metric and most things will be based on it.
Alright, buckle up because we're about to delve into the world of predictive modeling.
Predictive Modeling
Predictive modeling is a process of using statistical and machine learning techniques to create models that make predictions about future events or outcomes. It involves analyzing historical data and identifying patterns and relationships that can be used to forecast or estimate future behavior.
The primary goal is to develop a reliable model that can accurately predict outcomes for new or unseen data based on the patterns observed in the training data. The process typically involves several steps:
- Data Collection
- Data preprocessing
- Feature selection and engineering
- Model selection
- Model training
- Model Evaluation
- Model tuning and optimization
- Deployment and prediction
I tested several Classification Machine Learning Models that include Logistic Regression, XGBoostClassifier, KNeighbors, etc
So I had to decide the model to go with so that I can further tune it to improve performance.

I discovered single isolated algorithms are not performing well especially since they weren’t performing well on patients that have stroke. Yet this is the most important thing we want the model to be good at.
Let's see how different single-isolated models performed;
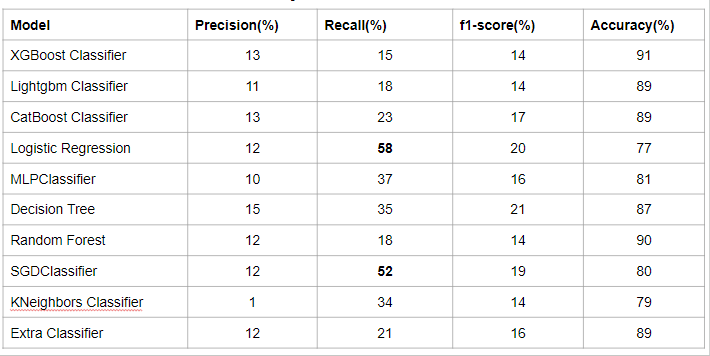
As you can see, single isolated algorithms were not reliable and that's when I decided to ensemble several models together to improve performance.
Well, you might ask, what is Ensemble Modeling??
Ensemble Modeling
This is a machine learning approach in which multiple learning algorithms are combined together in order to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
So I ensembled Logistic Regression and SGDClassifier because they were the better single performers.
I then turned the Ensemble model with state-of-the-art tuning using Optuna & Gridsearchcv which improved performance.
Let's now have a look at how the Ensemble model performed after tuning.
Model Performance
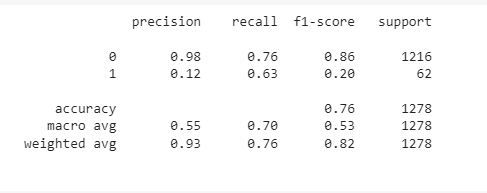
- The model has a recall of 63% for the positive class meaning that it can predict 63% of the time people with stroke.
- The model also has a precision of 98% for the negative class meaning that it can predict 98% of the time people who don’t have stroke.
- It also has an overall accuracy of 76%.
Let me now take the most impactful and exciting part of the project.
Model Deployment.
This is the most impactful part of the project and it's where we put our model out to the public for users to give it a shot. You don’t make an impact when your model is stagnant in Notebooks and Github.
In fact, between 60%-90% of Machine Learning models don’t make it to Production.
I used Streamlit, an easy-to-use Python Library that provides a faster way to build and share data apps.
The app takes 10 different input features in order to provide Stroke prediction.
Here's the app... Give it a try and maybe even break it
Challenges Faced
Just like with anything in Life, nothing is perfect and that's why we faced challenges along the process.
- Target Imbalance. This has been the biggest challenge for this project and it made the modeling very difficult.
Recommendations moving forward.
Honesty, the one big recommendation moving forward is to get more data points about people with stroke and solve the target imbalance going into modeling because if that gets solved, everything else will fall in place and it will enable us to get a much more reliable model.
Conclusion
Thanks for coming up to this point and reading until here. This project has been both exciting and in which I learned a lot. I hope you have also learned a few things that can help you in your journey
Here is the github repo with all the code.
Email: Kamalmohapy@gmail.com