Digital Data is the new software code.


In the ever-evolving landscape of technology, the emergence of Artificial Intelligence (AI) has become a force that everyone speaks about it. From self-driving cars to virtual assistants, ChatGPT and many more, AI has permeated various aspects of our lives. However, behind the scenes, there lies a crucial element that often goes unnoticed - THE POWER OF DATA. Join me now, we will explore the intrinsic connection between better data and better AI, shedding light on the importance of an outstanding data strategy and its parallel to software code strategy. Drawing inspiration from the profound words of British Mathematician Clive Humby that "Data is the new oil", we embark on a journey to discover the secrets of successful AI development, where data takes center stage.
It's hard to start, right? : Data Strategy.
Just as writing flawless code is crucial in software development, having the right data strategy is equally vital for AI systems. Businesses must recognize that AI is only as good as the data it learns from. To unlock AI's true potential, organizations need to invest in acquiring high-quality, diverse, and relevant data. This means going beyond form just quantity and focusing on data quality, integrity, and representativeness. Just as we embrace and enjoy utilizing tools like ChatGPT, Midjourney, Wondersdynamics, and other fascinating AI technologies, it is essential to understand that all of this would not have been possible without the efforts made in preparing and constructing accurate data systems for AI development. Without the existence of what we refer to as data, artificial intelligence would not exist.
Today, data is life. Anyone who invests their efforts in utilizing data has an opportunity to advance their lives as well as business. In our present world, there is a powerful concept that software engineers have embraced called DevOps. It is a technology that enables the seamless development of software products until completion. Given the significant demand for AI technologies, everything revolves around how it functions within AI systems. The strength and style we have employed in crafting our software codes should be applied when working with data. Data is the new language of programming and serves as the very code itself in the current landscape.
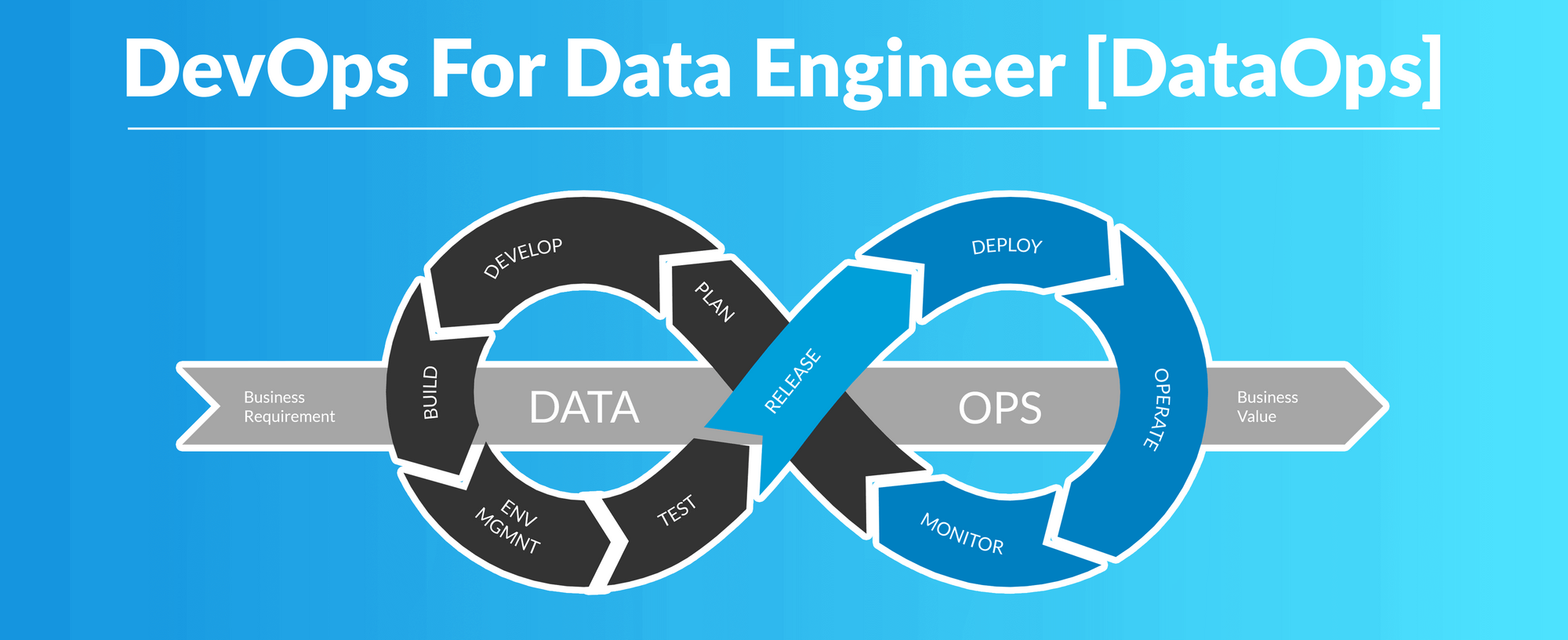
DataOps, which combines data engineering form start to completion like the way applied in software engineering, involves the use of various tools to streamline data operations and enhance collaboration between teams. Here are some examples of tools commonly used by data scientists in DataOps:
Version Control Systems (VCS): Tools like Git and GitHub enable data scientists to track changes, collaborate on code repositories, and manage different versions of code and data pipelines. Well, this is very known.
Data Integration and ETL( Extract, Transform and Load) Tools: Platforms like Apache Airflow, Apache Kafka, and Apache Nifi help with data integration, extraction, transformation, and loading (ETL) processes. These tools enable data scientists to simplify complex workflows and manage data pipelines efficiently.
Data Exploration and Visualization Tools: Tools like Tableau, Power BI, and Plotly assist data scientists in visually exploring and analyzing data. These tools offer interactive dashboards, charts, and visualizations to gain insights and communicate findings effectively.
Machine Learning and Statistical Libraries: Popular libraries like scikit-learn, TensorFlow and PyTorch provide data scientists with a wide range of machine learning algorithms, statistical models, and frameworks to develop and train AI models efficiently.
Data Quality and Monitoring Tools: Tools such as Great Expectations, Apache Atlas, and Prometheus help ensure data quality, validate data pipelines, and monitor the performance of data-driven applications.
Collaboration and Documentation Tools: Platforms like Jupyter Notebook and Google Colab enable data scientists to collaborate, share code, document workflows, and communicate findings within their teams.
Containerization Tools: Docker and Kubernetes are popular tools for containerizing data science applications and enable their deployment and scaling across different environments.
Automated Testing and Continuous Integration Tools: Data scientists use tools like Jenkins, Travis CI, or CircleCI for automating testing processes, continuous integration, and deployment of data pipelines.
Cloud Computing Platforms: Services like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure provide a range of cloud-based resources, such as storage, computing power, and managed services, that data scientists can leverage for scalable and cost-effective DataOps workflows.
Traditional Approaches Reimagined:
In the realm of software development, tried and tested methodologies govern the writing of code, testing, and deployment. Similarly, in the context of AI, a similar approach can be adopted for data. The data development lifecycle can mirror the software development lifecycle, from data acquisition and preprocessing to training and evaluation. This structured approach ensures that data is treated with the same rigor and importance as code, creating a solid foundation for AI systems.
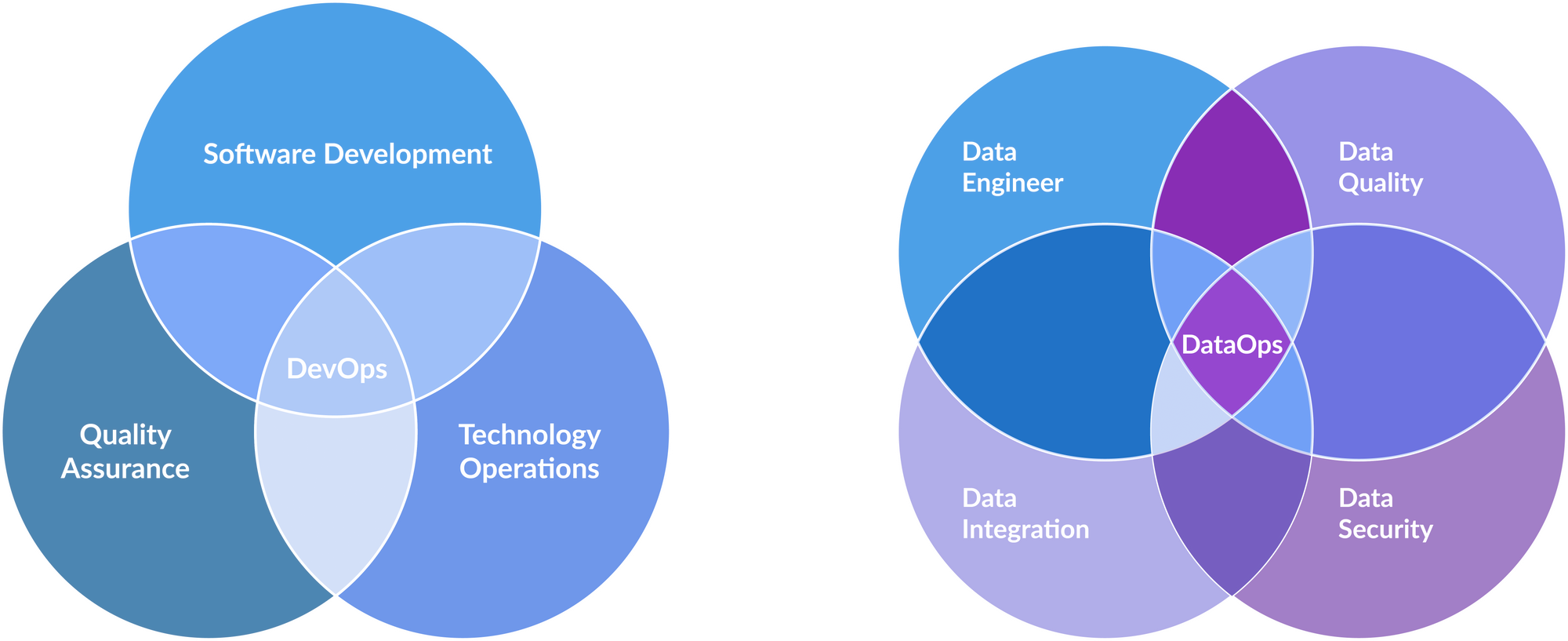
So what is the journey to completion?
Data Acquisition: The First Step: Just as software engineers gather requirements, the process of data acquisition demands careful consideration. Businesses should identify the sources of data, both internal and external, that hold the potential to enrich their AI systems. Whether it is through partnerships, data collaborations, or the development of in-house data collection tools, acquiring the right data sets the stage for AI success.
Data Preprocessing: Shaping the Raw Material: Just as developers refine raw code into a polished application, data preprocessing is essential to transform raw data into a format suitable for AI algorithms. This involves cleaning, filtering, and organizing the data to ensure its quality, consistency, and compatibility with the AI system's requirements. A well-defined data preprocessing strategy helps eliminate noise and bias, resulting in a more accurate and reliable AI model.
Training and Evaluation: Iterative Improvement: Much like the iterative nature of software development, AI models require continuous training and evaluation. The data strategy should encompass techniques for training AI systems using the collected data, fine-tuning the algorithms, and validating their performance against predefined metrics. This iterative process ensures that the AI system learns and adapts to changing circumstances, improving its accuracy and effectiveness over time.

Do not be surprised, they are just numbers that propel the world forward.
In the pursuit of AI development, we must confront the elephant in the room - the data bottleneck. So here, without high-quality data, AI systems cannot reach their full potential. Recognizing this bottleneck is crucial for businesses to allocate adequate resources, invest in data collection and curation, and leverage advanced techniques such as data augmentation and synthetic data generation to overcome limitations.

Investing in Data: A Leap of Faith and foundation of AI development.
Investing in data is, indeed, a leap of faith in AI development. Just as software companies invest heavily in code development and maintenance, organizations must realize that investing in data is equally critical for the success of their AI initiatives. A comprehensive data strategy aligns business objectives with the power of AI, enabling companies to make data-driven decisions, unlock new opportunities, and gain a competitive edge in the digital era.
In the fast-paced world of AI, the new AI applications lies in the power of data. Businesses must shift their mindset and consider data as the lifeblood of AI development. By formulating and implementing the right data strategy, organizations can unleash the true potential of AI, shaping a future where better data leads to better AI. It is through this leap of faith that we can embark on a transformative journey, harnessing the power of data to drive innovation, solve complex problems, and shape a brighter tomorrow.
Greetings, dear fans!
Today marks the beginning of an exciting journey where I will share with you the various ways we can embark on venturing with data, all in support to advance Artificial Intelligence systems. Artificial Intelligence has become a topic on everyone's lips, but for it to truly excel and touch every aspect of our lives, we must grasp its foundational building block. Today, I am thrilled to the start of my series on crafting AI models, conducting data analysis, and exploring the intricacies of data to illuminate our path forward.
Until we meet again, goodbye and take care!
Let's have a chat MgasaLucas