Data augmentation in natural language processing
This article will expose various techniques for augmenting data in Natural Language Processing.


Data augmentation has been the magic solution in building powerful machine learning solutions as algorithms are hungry for data, augmentation was commonly applied in the Computer vision field, recently seen increased interest in Natural Language Processing due to more work in low-resource domains, new tasks, and the popularity of large-scale neural networks that require large amounts of training data. Even with this recent upsweep, this area is still relatively untraversed, which may be due to the nature of language data with a range of challenges.
Today I will be sharing a range of data augmentation techniques, that can be used to reduce the thirst for data of machine learning algorithms.
But wait! what is the meaning of data augmentation?
According to Wikipedia, Data augmentation in data analysis is a technique used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from original data. It acts as a regularizer and helps in reducing over-fitting when training a machine learning model.
Was that helpful? Ooh! don't worry how about this below :)
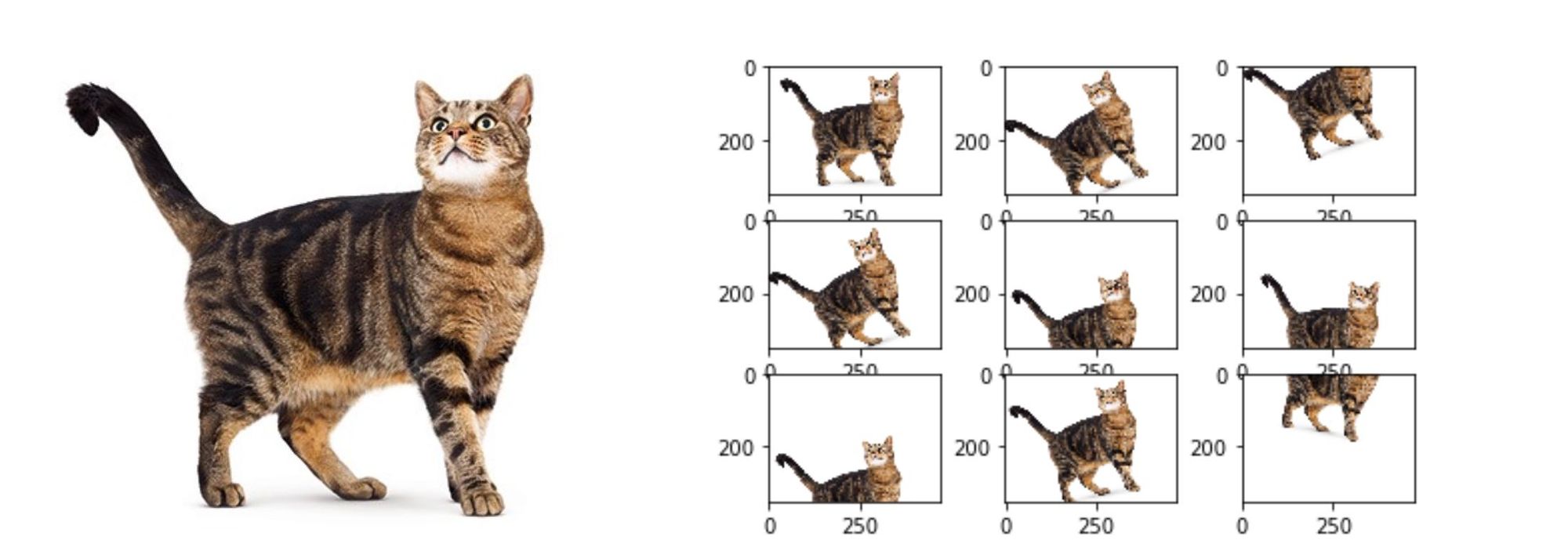
Data augmentation strategies are for increasing the diversity of training examples without explicitly collecting new data. It has received active attention in recent machine learning research in the form of well-received and general-purpose techniques.
Data Augmentation methods in NLP
Based on validity, the augmented data is expected to be various for a better generalization capacity of the downstream methods. This involves the diversity of augmented data. Different diversity involves different methods and the corresponding augmentation effects. In this article, I will be covering some of the commonly used augmentation techniques in NLP:)
Word Embeddings:- basically a form of word representation that bridges the human understanding of language to that of a machine. They have learned representations of text in an n-dimensional space where words that have the same meaning have a similar representation. This means that two similar words are represented by almost similar vectors that are very closely placed in a vector space. In this case methods like GloVe were applied to create new text by replacing the original text with the phrase or words that are synonyms. Curious about the implementation, here you go.
Back translation:- describes translating text from one language to another and then back from the translation to the original language. Machine translation tools are used to perform such tasks. Back translation leverages the semantic invariances encoded in supervised translation datasets to produce semantic invariances for the sake of augmentation. Also interestingly, back-translation is used to train unsupervised translation models by enforcing consistency on the back-translations. This form of back-translation is also heavily used to train machine translation models with a large set of monolingual data and a limited set of paired translation data.
ThesaurusLanguage translation APIs like google translate, Bing, and Yandex are used to perform the translation. Take a look at the below example, the Google translate used
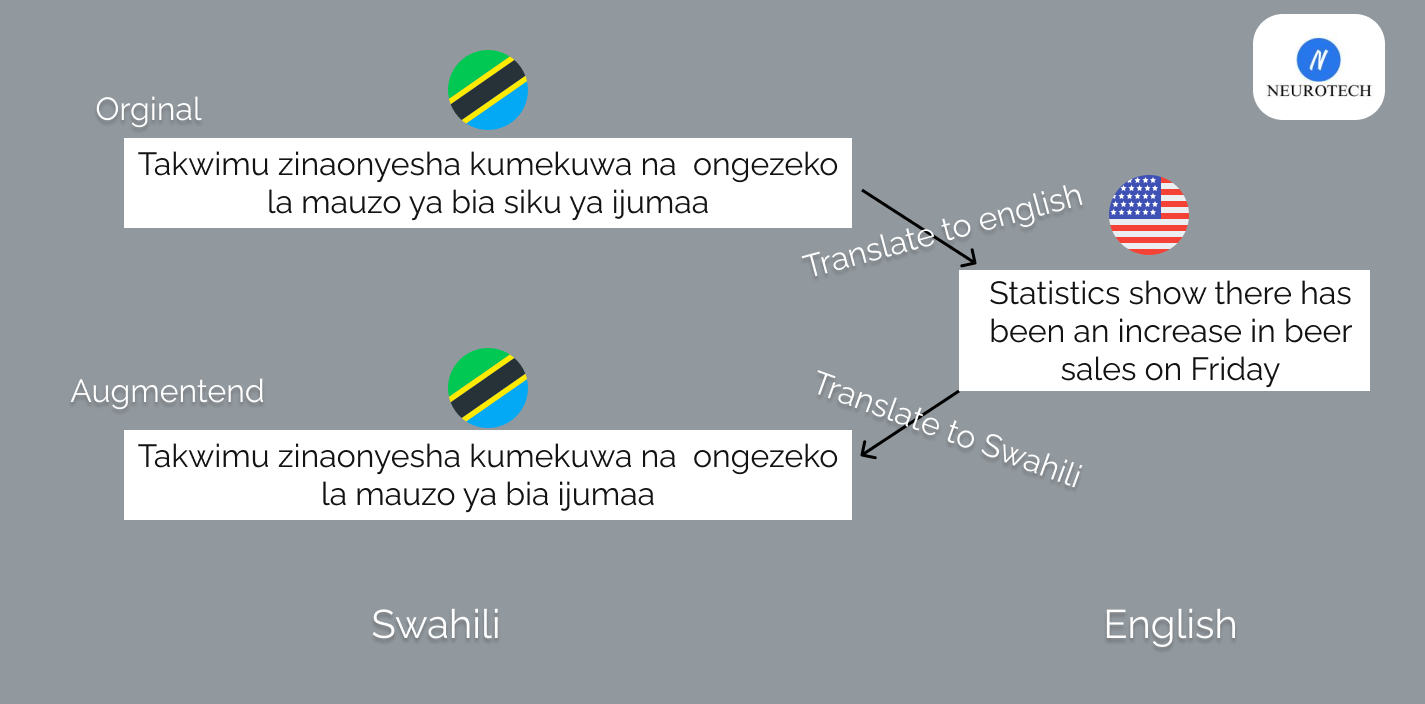
You can see that the Swahili sentences are not the same but their content remains the same after the back-translation. Curious about trying your own languages here you go.
Random Insertion:- among the traditional and very simple data augmentation methods introduced in the Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks paper. It involves finding a random synonym of a random word in the sentence that is not a stop word. Insert that synonym into a random position in the sentence. Do this n times.
Let's consider the example below
Most of this year's candidates are hardworking people.The words candidates and hardworking find the synonyms as applicants and diligent respectively. Then these synonyms are inserted at a random position in the sentence as below.
Most of this year's applicants are deligent people.Random Swap:- another method introduced in the Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks paper. It involves randomly choosing two words in the sentence and swapping their positions. Do this n times.
Let's consider the example below
The only thing you watch on TV is football and the last 'book' you read was a bicycle magazine.Then words football and bicycle are swapped to create a new sentence as below.
The only thing you watch on TV is bicycle and the last 'book' you read was a football magazine.Shuffle Sentences Transform:- it involves the shuffling of sentences in the text to create an augmented version of the original text, this technique can be achieved using the Albumentation package.
Let's consider the example below
In today's world, there is no shortage of data. But the quality of information means nothing without the ability to understand it.
Then after applying shuffle sentences transform
But the quality of information means nothing without the ability to understand it. In today's world, there is no shortage of data.
This can be done on a text with multiple sentences depending on the nature of the challenge.
Random Deletion:- this technique involves deleting some words especially stop words in the text to change the length of the text but remain with the same meaning. It is also introduced in the Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks paper.
Let's consider the example below
But the quality of information means nothing without the ability to understand it.
Then after applying random deletion
The quality of information means nothing without the ability to understand it.
Noise injection:- this is the method applied in the audio dataset, simply by adding random values into data by using NumPy.
Here you go
import numpy as np
def augment_data(data, noise_factor):
"""
python program to add noise in audio data
"""
noise = np.random.randn(len(data))
augmented_data = data + noise_factor * noise
# Cast back to same data type
augmented_data = augmented_data.astype(type(data[0]))
return augmented_dataChanging pitch of the audio:- in this technique python package for audio analysis like Librosa is the best tool to go with, by adding effect on the audio pitch to create new audio data.
Here you go
import librosa
def augment_data(data, sampling_rate, pitch_factor):
"""
python program to add effect on audio pitch
"""
augmented_data = librosa.effects.pitch_shift(data, sampling_rate, pitch_factor)
return augmented_data
Changing speed:- this technique can be achieved by using audio analysis packages like Librosa, by changing the speed of the original audio to slow or fast.
Here you go
import librosa
def manipulate(data, speed_factor):
"""
python program to change speed rate of an audio
"""
return librosa.effects.time_stretch(data, speed_factor)Also, you can read more on Feature space augmentation and Generative data augmentation techniques
Keep in mind that not every technique is applicable in any case, be careful on choosing the right augmentation technique depending on the use case at hand.
References
- Steven Y. Feng, et al. A Survey of Data Augmentation Approaches for NLP
- Jason Wei, et al. Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- Shahul ES Data Augmentation in NLP
- Edward Ma Data Augmentation for Audio