Data Augmentation: Expanding Possibilities in Machine Learning

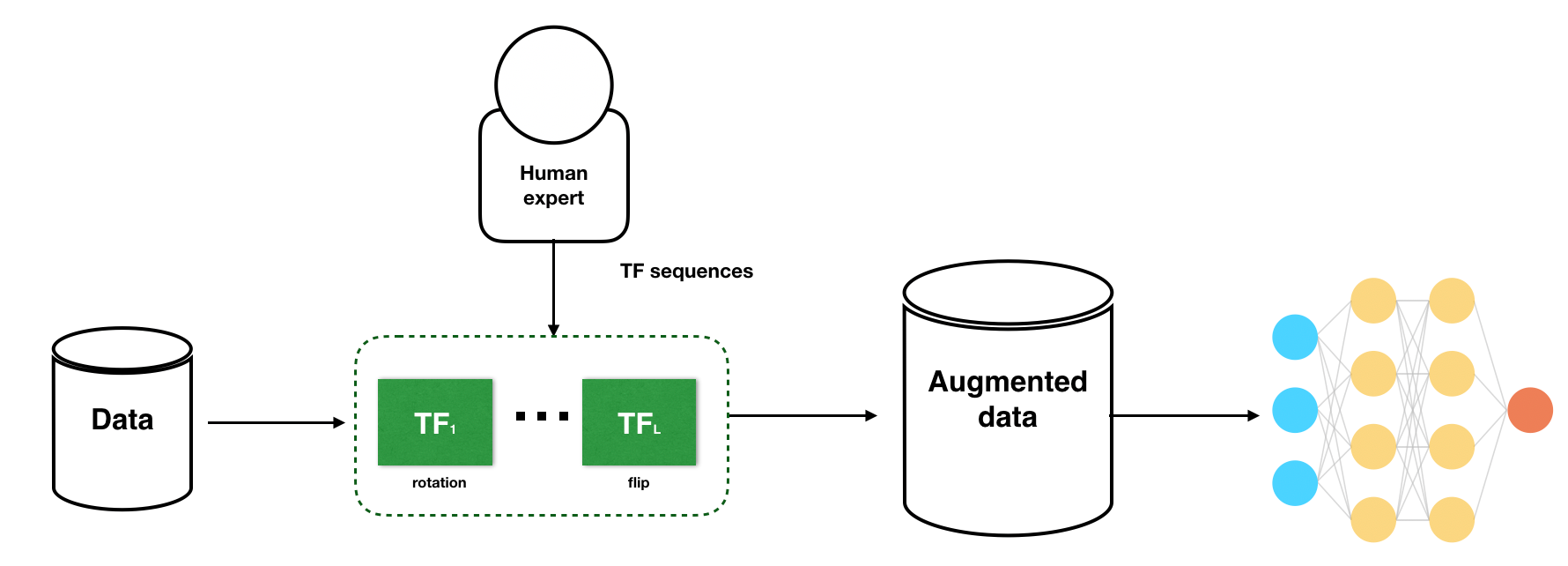
Introduction
Data augmentation is a powerful technique used to enhance machine learning datasets by generating additional samples through various transformations. By leveraging data augmentation, we can overcome the limitations of limited training data, improve model generalization, and boost overall performance. In this article, we explore the concept of data augmentation, its benefits, techniques, and considerations for effective utilization.
What is Data Augmentation?
Data augmentation involves applying transformations and variations to existing data, resulting in an expanded dataset. It allows us to create new samples while preserving the underlying patterns and characteristics of the original data. By introducing diverse perspectives, data augmentation enhances the model's ability to learn and generalize effectively.
Why Data Augmentation and When to Use It?
Data augmentation addresses the challenge of insufficient training data. It is particularly valuable in scenarios where collecting more labeled data is costly or time-consuming. By augmenting the available data, we can increase the dataset size, improve model robustness, and mitigate overfitting, especially when dealing with complex tasks and limited data availability.
Different Data Augmentation Techniques and Their Applications
Image Augmentation:
- Techniques: Rotation, Flipping, Scaling, Cropping, Color jittering
- Use cases: Object recognition, Image classification, Computer vision tasks
Text Augmentation:
- Techniques: Synonym replacement, Random word insertion/deletion, Character-level perturbations
- Use cases: Natural language processing, Text classification, Sentiment analysis
Numeric Augmentation:
- Techniques: Scaling, Adding noise, Random perturbations
- Use cases: Regression, Time series analysis, Numerical forecasting
Categorical Augmentation:
- Techniques: One-hot encoding, Introducing misspellings/variations
- Use cases: Classification, Recommendation systems, Multi-label prediction
Advantages of Data Augmentation
Increased dataset size and diversity, improving model generalization.
Reduced risk of overfitting by exposing models to a wider range of variations. Cost-effective alternative to collecting and annotating additional data. Enhanced model performance, especially in scenarios with limited training data.
Disadvantages of Data Augmentation
Augmented samples may introduce biases or distort the original data distribution. Care must be taken to avoid introducing unrealistic or improbable samples. Augmentation techniques may require domain expertise and fine-tuning. Computation and time-intensive process, especially for large datasets.
Data augmentation empowers us to overcome data scarcity challenges, improving the performance and generalization capabilities of machine learning models. By leveraging various augmentation techniques tailored to the data and task at hand, we can expand the dataset, enhance diversity, and unlock the potential of limited training data. It is essential to carefully consider the advantages, disadvantages, and domain-specific requirements to maximize the benefits of data augmentation in machine learning applications.
Time to get hands dirty.
To provide a practical demonstration of data augmentation, I created a sample car dataset and applied augmentation techniques to increase its size and diversity. Let's walk through the implementation and code snippets used.
Dataset Creation:
I created a dataset consisting of 1500 car records with columns such as Car Model, Car Brand, Car CC, Fuel Type, Car Color, Year of Manufacture, Mileage, and Price. This dataset served as the foundation for our augmentation process.
import random
car_models = ["Toyota Camry", "Honda Civic", "Ford Mustang", "BMW X5", "Nissan Sentra", "Tesla Model 3", "Chevrolet Cruze", "Hyundai Sonata", "Audi A4", "Volkswagen Golf"]
car_brands = ["Toyota", "Honda", "Ford", "BMW", "Nissan", "Tesla", "Chevrolet", "Hyundai", "Audi", "Volkswagen"]
car_cc = [2000, 1500, 3500, 3000, 1800, "N/A", 1600, 2500, 2000, 1400]
fuel_types = ["Petrol", "Petrol", "Petrol", "Diesel", "Petrol", "Electric", "Petrol", "Petrol", "Diesel", "Petrol"]
car_colors = ["Red", "Blue", "Black", "White", "Silver", "Gray", "Red", "Blue", "Black", "Green"]
year_of_manufacture = [random.randint(2000, 2023) for _ in range(1500)]
mileage = [random.randint(0, 150000) for _ in range(1500)]
price = [random.randint(5000, 50000) for _ in range(1500)]
dataset = []
for _ in range(1500):
car_model = random.choice(car_models)
car_brand = random.choice(car_brands)
cc = random.choice(car_cc)
fuel_type = random.choice(fuel_types)
color = random.choice(car_colors)
year = year_of_manufacture.pop(0)
car_mileage = mileage.pop(0)
car_price = price.pop(0)
dataset.append([car_model, car_brand, cc, fuel_type, color, year, car_mileage, car_price])
Exploratory Analysis
Before applying data augmentation, I conducted an exploratory analysis of the dataset to gain insights into its characteristics. I printed the first few rows, calculated summary statistics, and determined unique value counts for each column. This analysis helped us identify areas for augmentation and understand the dataset's distribution.
import pandas as pd
import matplotlib.pyplot as plt
# Load the dataset from the CSV file
df = pd.read_csv('car_dataset.csv')
# Perform exploratory analysis
print("Sample Data:")
print(df.head())
print("\nSummary Statistics:")
print(df.describe())
print("\nUnique Value Counts:")
print(df.nunique())
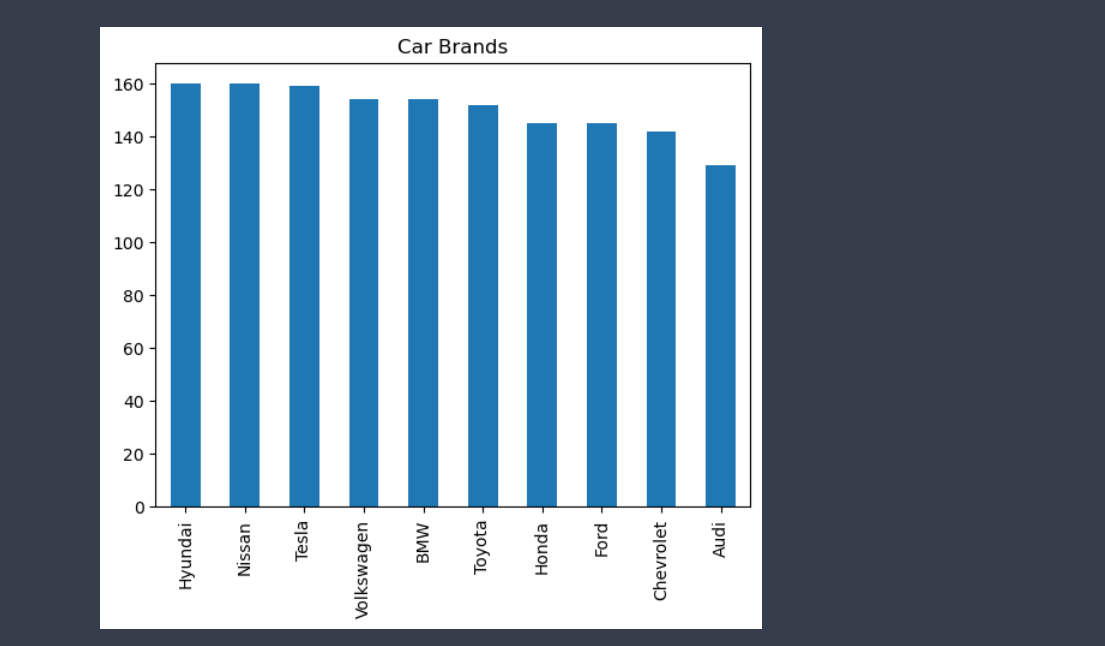
# Generate a bar chart of car brands
df['Car Brand'].value_counts().plot(kind='bar', title='Car Brands')
# ... Perform other exploratory analysis as desired
# Save the plot as an image
plt.savefig('car_brands.png')
# Print a message indicating the completion of the exploratory analysis
print("\nExploratory analysis completed!")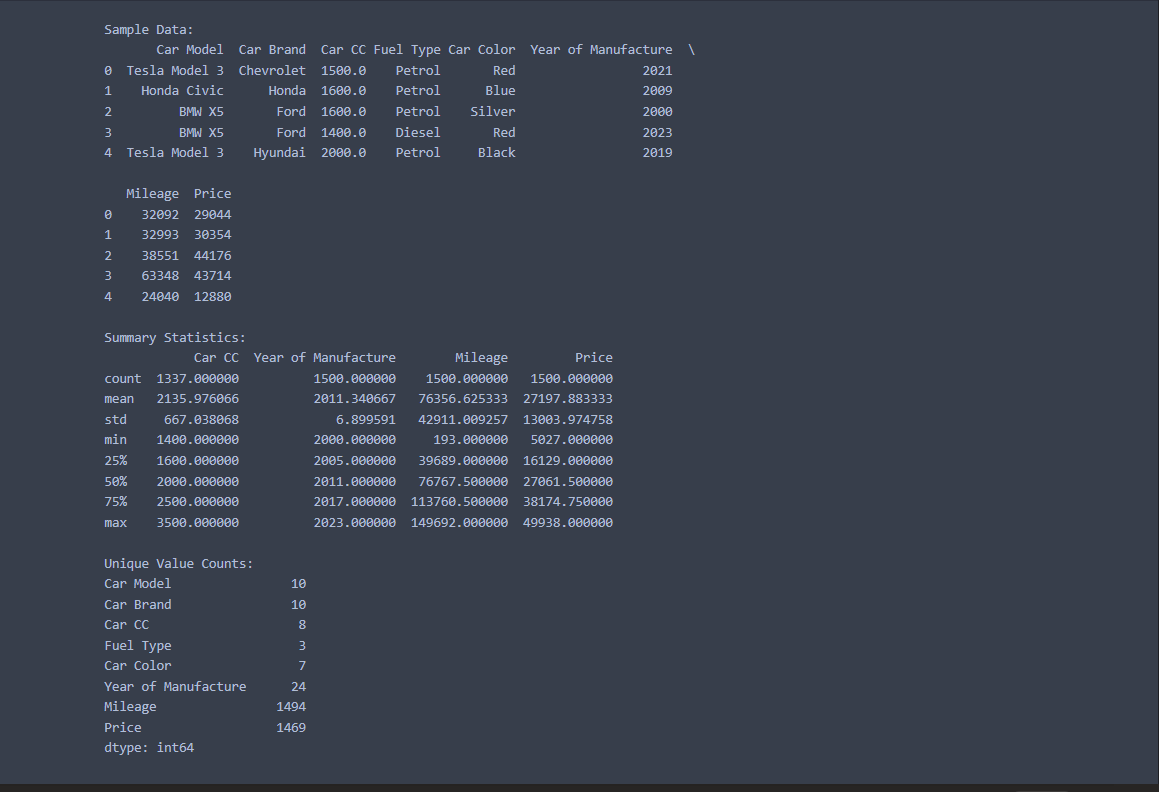
Data Augmentation Techniques: I applied various data augmentation techniques to expand and diversify the car dataset. Here are some code snippets representing the augmentation techniques used:
# Load the original dataset from the CSV file
df_original = pd.read_csv('car_dataset.csv')
# Define the desired augmented dataset size
desired_size = 5000
# Create an empty list to store augmented data
augmented_data = []
# Augmentation functions
def synonym_replacement(text):
# Placeholder function for synonym replacement
return text
def random_word_insertion(text):
# Placeholder function for random word insertion
return text
def character_perturbation(text):
# Placeholder function for character perturbation
return text
def scaling(value):
# Placeholder function for scaling
return value
def add_noise(value):
# Placeholder function for adding noise
return value
def random_perturbation(value):
# Placeholder function for random perturbation
return value
def one_hot_encoding(category):
# Placeholder function for one-hot encoding
return category
def introduce_misspelling(category):
# Placeholder function for introducing misspelling
return category
# Apply augmentation techniques to generate new samples
while len(augmented_data) < desired_size:
# Randomly select a row from the original dataset
original_row = random.choice(df_original.values.tolist())
# Apply augmentation techniques to generate new samples
augmented_row = original_row.copy()
augmented_row[0] = synonym_replacement(augmented_row[0])
augmented_row[1] = random_word_insertion(augmented_row[1])
augmented_row[0] = character_perturbation(augmented_row[0])
augmented_row[2] = scaling(augmented_row[2])
augmented_row[6] = add_noise(augmented_row[6])
augmented_row[7] = random_perturbation(augmented_row[7])
augmented_row[3] = one_hot_encoding(augmented_row[3])
augmented_row[4] = introduce_misspelling(augmented_row[4])
augmented_data.append(augmented_row)
# Create a DataFrame from the augmented data
df_augmented = pd.DataFrame(augmented_data, columns=df_original.columns)
# Save the augmented dataset as a new CSV file
df_augmented.to_csv('augmented_car_dataset.csv', index=False)
# Print a message indicating the completion of data augmentation
print("Data augmentation completed. Augmented dataset saved as augmented_car_dataset.csv with", len(df_augmented), "records.")
Data augmentation completed. Augmented dataset saved as augmented_car_dataset.csv with 5000 records.You can see that I have increased the size of our dataset from 1500 records to 5000 records.
Conlusion
Data augmentation presents immense opportunities to enhance machine learning models by leveraging existing data effectively. By incorporating augmentation techniques tailored to specific datasets, I can overcome the limitations of limited training data and foster improved model performance.
Remember to customize and expand upon the code snippets and practical implementation details to align with your specific dataset and augmentation requirements.
Author: Nyanda Freddy
Email: freddynyanda@proton.me