Building Swahili Question Answering App With Haystack
The Development of QA systems is one of the most diverse, fast-moving, and hot topics in the world of NLP and Business. Let's learn the implementation of Swahili Q & A with Haystack and how business leaders can leverage this to improve their customer experience.


The number of unstructured data just keeps growing! Classic search engines such as Google, Bing, etc. do help you to find certain documents on the web, but actually sifting through the wealth of documents for specific details is often left to the user ...
Question Answering can be used in a variety of use cases. A very common one: Using it to navigate through complex knowledge bases or long documents ("search setting"). A "knowledge base" could for example be your website, FQA, or a collection of financial reports.
Neurotech Africa is pioneering this, to help thousands of businesses across Africa thrive their business using custom Conversational AI experience. We have ready-made chatbots for all industries and provide third-party solutions that help developers in Africa integrate intelligence experience through our APIs.
Now let's dive into "What is Q and A and how to build with Haystack for Swahili language".
Meaning: Question and Answer
QA is a computer science field that applies information retrieval and NLP to construct systems in such a way that, given a question in natural language, one can extract relevant information from provided data and present it in the form of natural language answers.
This is one of the biggest, fascinating, fast-moving, and hot topics in the NLP and IR field, that, in fact, has been around for some time and used by big tech like google, amazon, apple, and Microsoft and world-class researchers to solve challenging problems in NLP.
Generally, QA models will receive a question, and (sometimes) extract an answer from a context, hence there are two types of QA systems,
Types of QA systems
Open-Domain(OD), we may be asking questions without providing context, the model has to find the answers elsewhere.
Reading Comprehension(RC), the context is provided to the model alongside the question, it is sometimes called extractive QA.
To this 'elsewhere' in open-domain, we can use either open-book or closed-book:
Open-Book vs Closed-Book Open-Domain QA system
Open-book is where the model has access to an external source of data, such as the internet (eg Wikipedia), or your own documents (eg company policy).
Closed-book is where the model relies on answers that it has encoded into its own parameters during training.
However, Building an end-to-end Open-Domain QA app is the hardest task, and time-consuming, In today's article, we will start by building the most applicable type which is Open-Domain Open-book with ease using an awesome framework called Haystack.
I have already built a Reading Comprehension QA app for the Swahili language, you can play with the complete Swahili QA app here or access the complete model as inference API. In the next article, I will explain also how to build an Open-Domain closed-book too.
Full QA Architecture: How does it work?
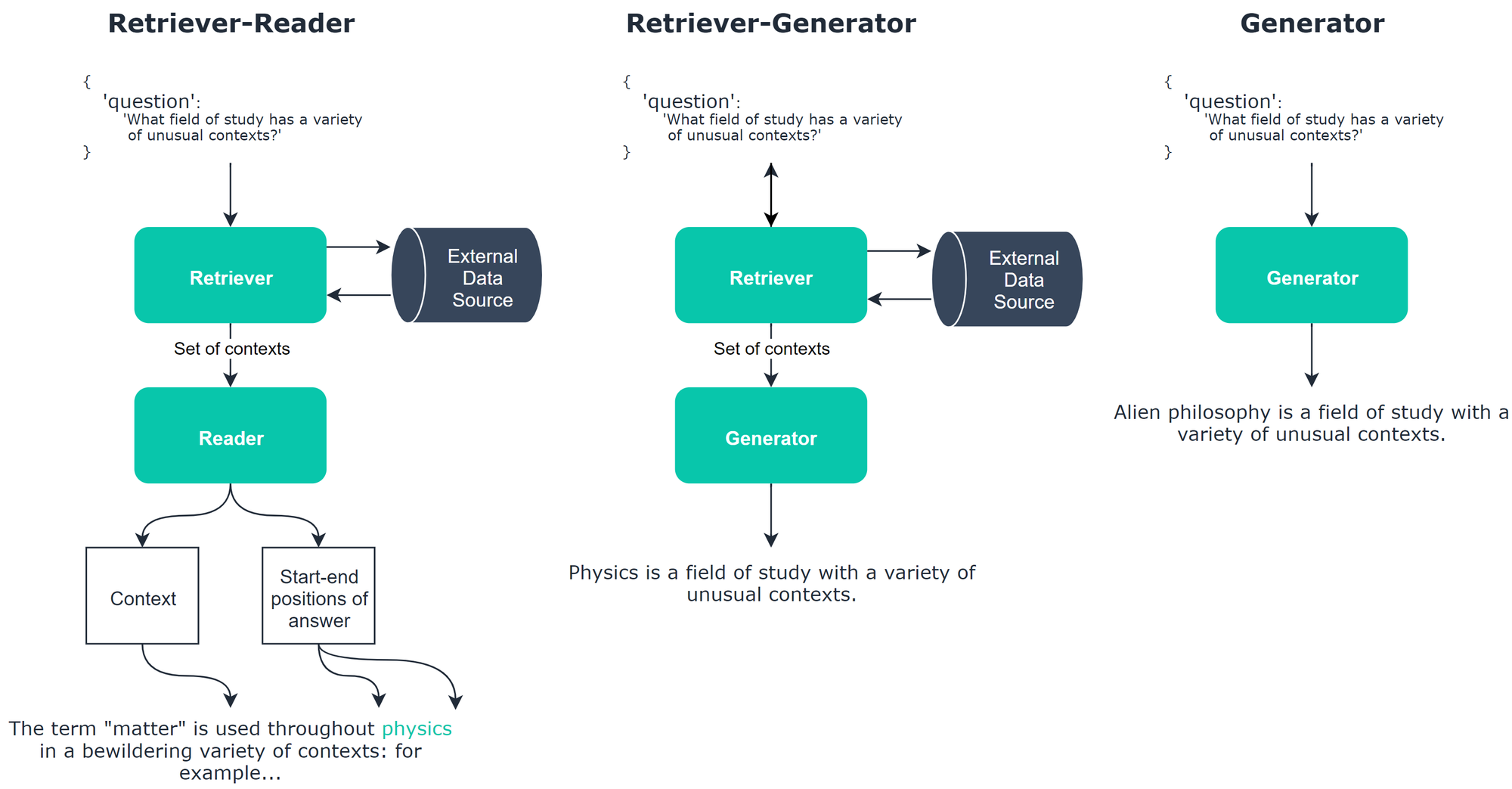
Today often we use a Question Answer approach, which may consist of a Reader, Retriever, or a Generator.
Retriever, this architecture retrieves a set of contexts for the Q&A model to extract answers from. The retriever extracts information from an external source and so this is only used in open-book.
Reader, this architecture takes a question and context and selects a span of the context that it believes answers the question. By itself, this produces a Reading comprehension model, but if paired with a retriever we create an Open domain model.
Generator, this architecture takes a question (and optionally a context) and generates an answer. Unlike the reader that extracts the answer from a context, the generator uses language generation to create an answer from scratch.
Generally: Those architectures, when applied to an effective together can result in Open Domain QA systems such that Retriever-Reader (open-book ODQA), Retriever-Generator (open-book ODQA), and Generator (closed-book ODQA) systems.
It's so difficult to build Open-domain QA since it requires integration of both Reader and Retriever, as well as proper handling of the training data.
However, we can make our lives much easier by using the Haystack framework by Deepset.AI, which is an NLP framework that allows us to perform 'Neural Question Answering at Scale'.,
Here we will explore it and use it to build our custom Open-Domain that consists of Retriever-Reader Architecture QA importantly using "The most spoken African Language ", Kiswahili. Hope you will find it interesting,!
Meaning: Haystack
Haystack is an open-source NLP framework that leverages pre-trained Transformer models. It enables developers to quickly implement production-ready semantic search, question answering, summarization, and document ranking for a wide range of NLP applications.
Haystack brought together distributed file systems such as Hadoop, Elasticsearch, and powerful transformer language models to easily develop intelligent QA systems at scale such as Retriever-Reader (open-book ODQA).
Swahili Q&A with Haystack
Now let's build our Swahili Question-Answer app using haystack, here will work on slightly different scenarios written in the Swahili language, such as Bendera ya Kenya, Ajari Haijali, Mjadala kuhusu athari za shughuli za kisiasa nchi, and n.k.., and we will use the app built to answer some questions related to that domain.
1. Environment setup:
Create a new folder and set up a virtual environment, use this guide to get started or you can also use Google colab with GPU, however, I recommend setting up a virtual environment.
Open the folder with the Jupyter notebook from Vscode, or with Google colab starts new project, and Install the latest version of the Haystack as follows below ...
! pip install git+https://github.com/deepset-ai/haystack.gitThen, configure how logging messages should be displayed and which log level should be used before importing Haystack, ignore warnings...consider the codes below
import logging
import warnings
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)
warnings.filterwarnings("ignore")
#Example log message: INFO - haystack.utils.preprocessing - Converting Data/0004_swa.txt Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily2. Document Store :
Create a Documentstore, Haystack finds answers to queries within the documents stored in a Document store. The current implementations of DocumentStore include ElasticsearchDocumentStore, FAISSDocumentStore, SQLDocumentStore, and InMemoryDocumentStore.
However, ElasticsearchDocumentStore is most recommended since it has preloaded features like full-text queries, BM25 retrieval, and vector storage for text embeddings.
Let's first start-up Elasticsearch, we will use it to save the document store containing our "knowledge base", those answers that we need the app to answer from upon asking the question,
Remember right ? ! This is Open Domain Open Book Q&A, since we will be asking the question to the app without giving it context, then the app will find the answer itself "elsewhere" from the document store stored externally in Elastic search, we will combine both Reader and Retriever together through Haystack.
Unlike Reading Comprehension, which the model is given both question and context together and always consists of Reader only, like this model here,
3. Start an Elasticsearch server :
This can be done either using docker image(recommended) or downloading it manually from the source,
from haystack.utils import launch_es
launch_es()
time.sleep(30)
# I have used the docker image to start the elasticsearch.
# Make sure you have docker first installed , then head to docker hub and pull the image for elasticsearch ,
#After having the image in the machine, you can use the above function from haystack to run the container of that images, hence the elasticsearch will be active and ready for our document store.However, you can download, install and start Elasticsearch manually as shown below
%%bash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
chown -R daemon:daemon elasticsearch-7.9.2
Now create the document store, leave everything as defaults
import os
from haystack.document_stores import ElasticsearchDocumentStore
host = os.environ.get("ELASTICSEARCH_HOST", "localhost")
document_store = ElasticsearchDocumentStore(host=host, username="", password="", index="document")
4. Preprocessing of data
Haystack provides a customizable pipeline for converting files into texts, cleaning texts, splitting texts, and writing them to a Document Store.
Here, I will use the data, which contains documents for a range of domains written in Swahili languages, the datasets contain more than 1231 documents with topics like Bendera ya Kenya, Ajari Haijali, Mjadala kuhusu athari za shughuli za kisiasa nchi, and n.k
#import the function to convert data into dict and clean the text.
from haystack.utils import clean_wiki_text, convert_files_to_docs
#The path of the data,I have used more than 1234 documents,that the answers will be found.
data_dir="../Data"
# Convert files to dicts
# You can optionally supply a cleaning function that is applied to each doc (e.g. to remove footers)
# It must take a str as input, and return a str.
data_cleaned=convert_files_to_docs(dir_path=data_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# We now have a list of dictionaries that we can write to our document store.
# If your texts come from a different source (e.g. a DB), you can of course skip convert_files_to_dicts() and create the dictionaries yourself.
# The default format here is:
# {
# 'content': "<DOCUMENT_TEXT_HERE>",
# 'meta': {'name': "<DOCUMENT_NAME_HERE>", ...}
# }
# (Optionally: you can also add more key-value-pairs here, that will be indexed as fields in Elasticsearch and
# can be accessed later for filtering or shown in the responses of the Pipeline)
#Now print the proccessed data,
print(f"Number of docs: {len(data_cleaned)}")
number=[0,1,2,3,5]
for x in number:
print(data_cleaned[x])
data_cleaned[1]
#Finally write the proccessed data into the document store created earlier.
document_store.write_documents(data_cleaned)
5. Initialize Retriever, Reader & Pipeline :
Create Retriever, help narrow down the scope for the Reader to smaller units of text where a given question could be answered. They use some simple but fast algorithms. Here we will use Elasticsearch's default BM25 algorithm
from haystack.nodes import BM25Retriever
retriever = BM25Retriever(document_store=document_store)
# Alternatives:
#Customize the BM25Retrieverwith custom queries (e.g. boosting) and filters.
#Use TfidfRetriever in combination with a SQL or InMemory Document store for simple prototyping and debugging
#Use EmbeddingRetriever to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)
#Use DensePassageRetriever to use different embedding models for passage and query
# Alternative: An in-memory TfidfRetriever based on Pandas dataframes for building quick-prototypes with SQLite document store.
# from haystack.nodes import TfidfRetriever
# retriever = TfidfRetriever(document_store=document_store)
Create Reader, A Reader scans the texts returned by retrievers in detail and extracts the k best answers. They are based on powerful learning models, such that of Swahili Question-Answer Model, which I explained earlier,
Haystack currently supports Readers based on the frameworks FARM and Transformers. With both, you can either load a local model or one from Hugging Face's model hub (https://huggingface.co/models).
In this tutorial, I will use Swahili Question-Answering Model, in the FARMReader which I created using Swahili datasets to perform the Question-Answer task, the model is publicly available in Hugging Face,
from haystack.nodes import FARMReader
#i have use the Transformer model for swahili QA that i created , it downloads from hugging face,
reader = FARMReader(model_name_or_path="innocent-charles/Swahili-question-answer-latest-cased", use_gpu=True)
#Alternative you can use the TransformersReader
from haystack.nodes import TransformersReader
# reader = TransformersReader(model_name_or_path="innocent-charles/Swahili-question-answer-latest-cased", tokenizer="innocent-charles/Swahili-question-answer-latest-cased", use_gpu=-1)Finally Create a Pipeline that combines Retriever and Reader both together, To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the ExtractiveQAPipeline which combines a retriever and a reader to answer our questions.
from haystack.pipelines import ExtractiveQAPipeline
pipeline_app = ExtractiveQAPipeline(reader, retriever)
Voilà! You can start asking a question to our system!:
# You can configure how many candidates the Reader and Retriever shall return
# The higher top_k_retriever, the better (but also the slower) your answers.
#And from here you can run as many as questions you want regards to the domains used to create this app ,
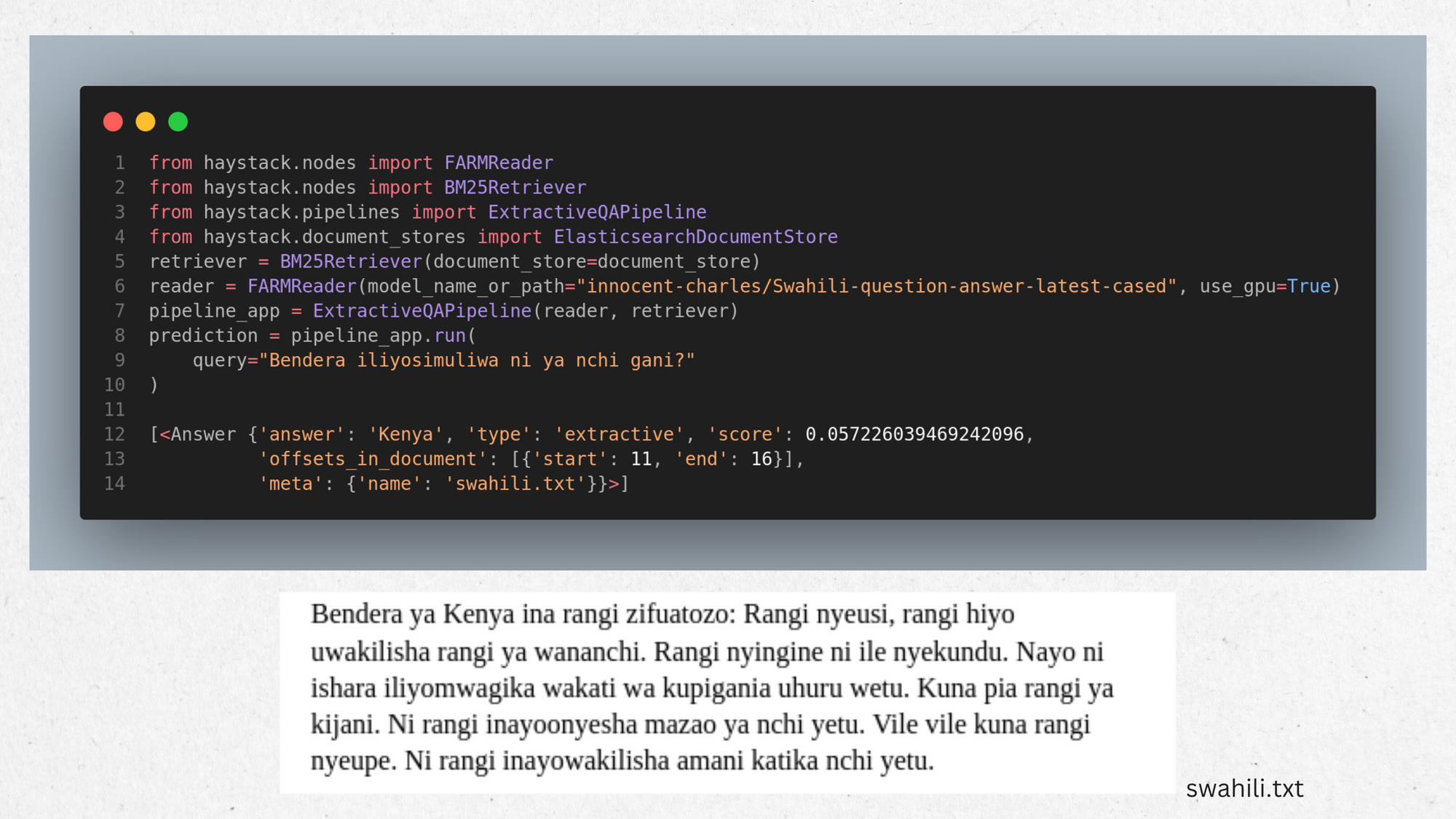
prediction = pipeline_app.run(
query="Bendera iliyosimuliwa ni ya nchi gani?", params={"Retriever": {"top_k": 1}, "Reader": {"top_k": 1}}
)
#Example you can train too in your own "Knowldge base" that might be FQA from your businesses,it can be info about your Businesses , of financial reports for your business.
#printing the answer
print_answers(prediction, details="minimum")6. Example :
Voila! You made it to the end, nice hacking! , that was easy, right?. Keep reading more on Haystack here and see other cool stuff it can do, am so curious to see what you can build with it,
At Neurotech, we offer intelligent QA solutions to business problems. Rather than documents being lost in an abyss, they can be stored within a space where an intelligent QA agent can access them. Unlike humans, our QA agent can scan millions of documents in seconds and return answers from these documents almost instantly.
We have managed to create our first simple Swahili QA with Haystack, from above we have learned about Question Answering, Haystack, and seen the implementation using the Swahili language, Great!, say " Hi " to me through Linkedin, I would be happy to share conversation about future of Artificial Intelligence and it's opportunities in our Africa.
