Bank Account Access Prediction


Predicting Bank Account Access in East Africa with Machine Learning
Introduction:
Financial inclusion remains a critical challenge in East Africa, where only 14% of adults across Kenya, Rwanda, Tanzania, and Uganda have access to or utilise a bank account. Traditional methods for assessing financial inclusion have proven limited, necessitating innovative approaches for more effective interventions. In response to this, our AI community (UDSM AI) has embarked on a project to leverage machine learning to predict bank account access in East Africa. This initiative aims to provide data-driven insights to policymakers and financial institutions, facilitating targeted interventions and product development strategies.
Project Goal:
Develop a machine learning model to predict bank account access across East Africa, providing data-driven insights to policymakers and financial institutions for targeted initiatives and product development.
Technical Approach:
- Utilise diverse machine learning algorithms on a comprehensive dataset encompassing demographic, socioeconomic, financial access, and behavioural data.
- Implement feature engineering, cross-validation, and model tuning for optimal performance and generalisability.
- Ensure model explainability and interpretability to translate insights into actionable recommendations.
Expected Outcomes:
- Improve bank account access prediction accuracy compared to existing methods.
- Identify key factors driving financial inclusion and exclusion in each East African country.
- Inform targeted financial inclusion initiatives and product development strategies.
- Contribute to increased bank account access and financial well-being in the region.
Target Audience:
- Financial institutions operating in the region.
- Researchers and academics focused on financial inclusion.
Next Steps:
- Develop and refine the machine learning model.
- Analyse and interpret model findings.
- Disseminate insights and recommendations to policymakers and financial institutions.
Project Implementation
1. Library Installation and Importation.
To kickstart our project, we begin by setting up our Python environment and installing then importing the necessary libraries. The following libraries are essential for data manipulation, visualisation, and machine learning model development:
a) Installation:
pip install pandas numpy seaborn matplotlib lightgbm scikit-learn missingno xgboost lightgbm
b) Importation:
# dataframe and plotting
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# machine learning
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# xgboost
import xgboost as xgb
import lightgbm as lgb
# multilayer perceptron
from sklearn.neural_network import MLPClassifier
# oversampling techniques to handle imbalanced data
from imblearn.over_sampling import RandomOverSampler as ROS
from imblearn.under_sampling import RandomUnderSampler as RUS
from collections import Counter
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
With our libraries in place, the next step is to load our dataset. Let's proceed with loading and understanding the data:
2. Data Loading and Understanding
In this step, we load our training and test datasets along with variable definitions. Also we go further into understanding the shape, structure, and characteristics of as it is foundational for the success of our project.
# Data loading
train = pd.read_csv('Train.csv')
test = pd.read_csv('Test.csv')
variables = pd.read_csv('VariableDefinitions.csv')
# Create a copy of the train dataframe
_train = train.copy()
# Let’s observe the shape of our datasets.
print('Train data shape:', train.shape)
print('Test data shape:', test.shape)
# Inspect train data
print('\nFirst Few Rows of Train Data:')
print(train.head())
# Check for missing values
print('\nMissing Values in Train Data:')
print(train.isnull().sum())
# Check for duplicated values
print('\nDuplicated Values in Train Data:')
print(train.duplicated().sum())
# Show some information about the dataset
print('\nTrain Data Information:')
print(train.info())
# View the variables
print('\nVariable Definitions:')
print(variables)
Here is what we have done in the code above:
- Loaded the Datasets.
- Created a copy of the Data frame for future use.
- Observed Datasets' Shapes.
- Inspected Training Data.
- Checked For Missing and Duplicated Values Values.
- Displayed Dataset Information.
- Observed Variable Definitions.
With our datasets loaded and understood, we move on to the next steps in our project, focusing on data pre-processing and exploratory data analysis.
3. Data Pre-processing
As we prepare our dataset for the next stages of Exploratory Data Analysis (EDA) and model development, we undertake data pre-processing. This involves tidying up the dataset, handling missing values, and ensuring data integrity.
# Visualize missing values using a bar chart
missingno.bar(train, figsize=(10, 5), sort='ascending', color='dodgerblue', fontsize=12);
# Check the sum and percentage of missing values
print('\nMissing Values Summary:')
print(train.isnull().sum())
print('')
percent_missing = train.isnull().sum() * 100 / len(train)
print(percent_missing)
# Visualize the location of missing values in the data
missingno.matrix(train, figsize=(10, 5), fontsize=12);
# Check the nullity correlation of different columns in the data
missingno.heatmap(train, cmap="RdYlGn", figsize=(10, 5), fontsize=12);
# Drop rows with missing values
train_cleaned = train.dropna()
print('\nDataset After Dropping Missing Values:')
print(train_cleaned.isnull().sum())
# Convert data types of float columns to int
train_cleaned['household_size'] = train_cleaned['household_size'].astype(float).astype(int)
train_cleaned['Respondent Age'] = train_cleaned['Respondent Age'].astype(float).astype(int)
print('\nData Types After Conversion:')
print(train_cleaned.dtypes)
# Drop specific values from the 'year' column
values_to_drop = [2029, 2056, 2039]
train_filtered = train[train['year'].isin(values_to_drop) == False]
print('\nDataset After Dropping Specific Values:')
print(train_filtered.shape)
In this section, we utilise the missingno module to visualise and handle missing values. The steps include:
- Visualising Missing Values.
- Checking Missing Values Summary.
- Visualising Location of Missing Values.
- Plotting a nullity Correlation Heatmap.
- Dropping Missing Values.
- Converting Data Types.
- Dropping Specific Values
With our dataset cleaned and pre-processed, we are now ready to delve into Exploratory Data Analysis (EDA) to uncover patterns and insights.
4. Exploratory Data Analysis (EDA)
Now, let's explore the data and uncover patterns and insights using various plots. EDA involves both univariate and bivariate analyses.
4.1 Univariate Analysis
Plot 1: Distribution of Respondent Age
# Setting colors for our plots
colors = ['#7FB3D5', '#73C6B6', '#F0B27A', '#C39BD3', '#ABEBC6', '#F4D03F']
# Analysing the numeric variables
trainn = train[['household_size', 'age_of_respondent']]
# Analyzing the distribution of respondent age
sns.displot(trainn['age_of_respondent'], bins=15, kde=True, color=colors[0])
plt.title('Distribution of Age', fontsize=20)
plt.ylabel('Count', fontsize=18)
plt.xlabel('Age Bin', fontsize=18)
plt.show()
Plot 2: Descriptive Statistics of Respondent Age
# Descriptive statistics of respondent age
pd.DataFrame(trainn['age_of_respondent']).describe()
Plot 3: Skewness and Kurtosis of Respondent Age
# Creating a function to truncate floats
def mytrim(float_number, length):
if isinstance(float_number, float):
num = str(float_number)
digits = num.split(".")
return_str = float(digits[0] + "." + str(digits[1])[:length])
return return_str
# Checking on the skewness of the data
y = mytrim(stats.skew(trainn['age_of_respondent']), 4)
print('The skewness of the respondent age is ' + str(y))
if y > 0:
print('\nThe tail on the right side is greater than that on the left side; the mean is greater than mode.')
else:
print('The tail on the left side is greater than that on the right side; the mode is greater than the mean.')
# Checking on the Kurtosis
x = mytrim(stats.kurtosis(trainn['age_of_respondent']), 4)
print('\nThe kurtosis of the data is ' + str(x))
if x == 0:
print('\nThe data displays a normal distribution; the data is mesokurtic.')
elif x > 0:
print('\nThe data is heavy-tailed and has a high degree of peakedness; the data is leptokurtic.')
else:
print('\nThe data is light-tailed; it has a low degree of peakedness; the data is platykurtic.')
Plot 4: Distribution of Household Sizes
# Analyzing the distribution of household sizes
sns.displot(trainn['household_size'], bins=15, kde=True, color=colors[1])
plt.title('Distribution of Household Sizes', fontsize=20)
plt.ylabel('Count', fontsize=18)
plt.xlabel('Household Size Bin', fontsize=18);
Plot 5: Descriptive Statistics of Household Sizes
# Descriptive statistics of household sizes
pd.DataFrame(trainn['household_size']).describe()
Plot 6: Skewness and Kurtosis of Household Sizes
# Checking on the skewness of the data
y = mytrim(stats.skew(trainn['household_size']), 4)
print('The skewness of the household size is ' + str(y))
if y > 0:
print('\nThe tail on the right side is greater than that on the left side; the mean is greater than mode.')
else:
print('The tail on the left side is greater than that on the right side; the mode is greater than the mean.')
# Checking on the Kurtosis
x = mytrim(stats.kurtosis(trainn['household_size']), 4)
print('\nThe kurtosis of the data is ' + str(x))
if x == 0:
print('\nThe data displays a normal distribution; the data is mesokurtic.')
elif x > 0:
print('\nThe data is heavy-tailed and has a high degree of peakedness; the data is leptokurtic.')
else:
print('\nThe data is light-tailed; it has a low degree of peakedness; the data is platykurtic.')
Plot 7: Pair Plot of Numerical Variables
# Creating the pair plot for our numerical variables
sns.pairplot(trainn, hue='bank_account')
plt.show()
4.2 Bivariate Analysis
Bivariate analysis involves examining relationships between pairs of variables. In this case, we explore the relationships between variables and bank account access.
Plot 8: Number of Respondents by Country
# Visualizing the countries' total respondents
x = train['country'].unique()
y = train['country'].value_counts()
# Making the bar chart on the data
plt.bar(x, y, color=colors)
# Calling the function to add value labels
addlabels(x, y)
plt.title('Number of Respondents', fontsize=18, fontweight='bold', color='teal')
plt.ylabel('Count', fontsize=18)
plt.xlabel('Country', fontsize=18)
plt.show()
Plot 9: Crosstab of Country and Individuals with Bank Account
# Creating a crosstab for the country and individuals with a bank account
df = pd.crosstab(train['country'], train['bank_account'])
df['percent'] = (df.Yes / (df.Yes + df.No)) * 100
df
Plot 10: Heatmap of Respondents with Bank Accounts
# Visualizing the percentages
adf = pd.crosstab(train['country'], train['bank_account'], margins=True, normalize=True, margins_name='Total').style.format('{:.2%}').background_gradient().set_caption('Heatmap of Respondents with Bank Accounts')
adf
Plot 11: Pie Chart of Age Brackets
# Creating a pie chart
train['gender_of_respondent'].value_counts().nlargest(10).plot(kind="pie", startangle=144, colors=colors, explode=(0.07, 0), autopct='%1.1f%%')
plt.title('Age Brackets of Our Respondents', fontsize=20, fontweight='bold', color='teal')
plt.axis('off')
plt.xlabel(None)
plt.ylabel(None)
plt.show()
Plot 12: Bar Plot of Gender Distribution
# Creating a bar plot
gender = train['gender_of_respondent'].unique()
res = train['gender_of_respondent'].value_counts()
plt.bar(gender, res, color=colors)
ax = plt.gca()
ax.get_yaxis().set_visible(False)
addlabels(gender, res)
plt.title('Gender of Respondents', fontsize=20, fontweight='bold', color='teal')
plt.xlabel(None)
plt.ylabel(None)
plt.show()
Plot 13: Crosstab of Education Level and Individuals with Bank Account
# Education level and individuals having bank accounts
df1 = pd.crosstab(train['education_level'], train['bank_account'])
df1['percent'] = (df1.Yes / (df1.Yes + df1.No)) * 100
df1.head()
Plot 14: Heatmap of Education Level and Respondents with Bank Accounts
# Checking on the percentage
adf = pd.crosstab(train['education_level'], train['bank_account'], margins=True, normalize=True, margins_name='Total').style.format('{:.2%}').background_gradient().set_caption('Heatmap of Respondents with Bank Accounts')
adf
Plot 15: Tree Map of Education Level
# Creating a tree map
import squarify
count = train['education_level'].value_counts()
ed = train['education_level'].unique()
plt.rc('font', size=17)
plt.figure(figsize=(14, 10))
squarify.plot(sizes=count, label=ed, color=colors, alpha=0.9)
plt.axis('off')
plt.title('Education Level', fontsize=20, fontweight='bold', color='teal')
plt.show()
Plot 16: Pie Chart of Education Level
# Creating a pie chart
plt.figure(figsize=(14, 10))
train['education_level'].value_counts().nlargest(10).plot(kind="pie", startangle=144, colors=colors, explode=(0.07, 0, 0, 0, 0, 0, 0), autopct='%1.1f%%')
plt.title('Level of Education of Our Respondents', fontsize=20, fontweight='bold', color='teal')
plt.axis('off')
plt.xlabel(None)
plt.ylabel(None)
plt.show()
Plot 17: Crosstab of Job Type and Individuals with Bank Account
# Creating a cross table to summarize the information
df6 = pd.crosstab(train['job_type'], train['bank_account'])
df6['percent'] = (df6.Yes / (df6.Yes + df6.No)) * 100
df6.head()
Plot 18: Heatmap of Job Type and Respondents with Bank Accounts
# Breaking the above information down into percentages
adf = pd.crosstab(train['job_type'], train['bank_account'], margins=True, normalize=True, margins_name='Total').style.format('{:.2%}').background_gradient().set_caption('Heatmap of Respondents with Bank Accounts')
adf
Plot 19: Correlation of Numerical Variables
# Checking on the correlation of the numerical variables
trainn.corr()
Plot 20: Scatter Plot of Respondent Age and Household Size
# Creating a scatter plot with a trend line
x = trainn['household_size']
y = trainn['age_of_respondent']
plt.plot(x, y, 'o')
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
plt.plot(x, p(x), "r--")
# The line equation:
print("y=%.6fx+(%.6f)" % (z[0], z[1]))
plt.xlabel('Household Size', fontsize=20, fontweight='bold', color='teal')
plt.ylabel('Respondent Age', fontsize=20, fontweight='bold', color='teal')
plt.title('Respondent Age and Household Size', fontsize=20, fontweight='bold', color='teal')
plt.show()
5. Feature Engineering
Feature engineering is a crucial step in the machine learning pipeline, where we transform and prepare our data to enhance the performance of our models. In this phase, we focus on processing features, handling categorical variables, scaling numerical features, and addressing class imbalance.
5.1 Preprocessing Features
Step 1: Convert Target Label to Numerical Data
Here, we use the LabelEncoder to convert the target variable ('bank_account') into numerical format.
# Convert target label to numerical data
le = LabelEncoder()
train['bank_account'] = le.fit_transform(train['bank_account'])
Step 2: Feature Scaling
Then we use MinMaxScaler to scale numerical features to a standard range, ensuring that all features contribute equally to the model.
# Scaling features
features_to_scale = ['household_size', 'age_of_respondent', 'year']
scaler = MinMaxScaler()
_features[features_to_scale] = scaler.fit_transform(features[features_to_scale])
Step 3: One-Hot Encoding for Categorical Variables
In this step we use One-hot encoding by applying it to categorical variables to convert them into a binary matrix representation.
# One-hot encoding for categorical variables
encoder = OneHotEncoder(sparse=False, drop='first', dtype=int)
_features_encoded = pd.DataFrame(encoder.fit_transform(_features[categorical_columns]), columns=encoder.get_feature_names_out(categorical_columns))
Step 4: Combine Encoded Features with Non-Categorical Features
In this step, the encoded features are then combined with the non-categorical features to form the final processed feature set.
# Combine encoded features with non-categorical features
_features_processed = pd.concat([_features.drop(columns=categorical_columns.drop('country')), _features_encoded], axis=1)
5.2 Addressing Class Imbalance
Step 5: Undersample the Majority Class
As observed in the plots during EDA there is a problem of class imbalance in the output variable, So to address class imbalance, RandomUnderSampler is employed to reduce the number of instances in the majority class.
# Undersample the majority class using RandomUnderSampler
rus = RUS(random_state=42)
_features, labels = rus.fit_resample(_features, labels)
5.3 Data Splitting for Each Country
Step 6: Data Splitting by Country
Data splitting is performed for each country to ensure a representative distribution in both training and testing sets.
# Initialize empty lists to store the split data for each country
train_data_splits = []
test_data_splits = []
# Iterate through each country and perform the split
for country in countries:
# Filter data for the current country
country_data = _train_[_train_['country'] == country].copy()
# Split data
_country_train, _country_test = train_test_split(country_data, test_size=0.1, random_state=42, stratify=country_data['bank_account'])
# Append data to lists
train_data_splits.append(_country_train)
test_data_splits.append(_country_test)
# Merge the data back together
_train_data = pd.concat(train_data_splits)
_test_data = pd.concat(test_data_splits)
_train_data = _train_data.drop(['country'], axis=1)
_test_data = _test_data.drop(['country'], axis=1)
Step 7: Finalize Train and Test Sets
The final step here involves extracting features and labels from the split data, resulting in the train and test sets ready for model training and evaluation.
# Extract features and labels from the split data
_train_features = _train_data.drop(['bank_account'], axis=1)
_train_labels = _train_data['bank_account']
_test_features = _test_data.drop(['bank_account'], axis=1)
_test_labels = _test_data['bank_account']
# Train data split
X_train, y_train = _train_features, _train_labels
X_test, y_test = _test_features, _test_labels
# Check the shapes of the train and test sets
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
This feature engineering process ensures that our data is appropriately prepared for machine learning model development, considering numerical scaling, one-hot encoding, and addressing class imbalance.
6. Model Development and Evaluation
In the model development phase, we leverage various machine learning algorithms to build predictive models based on our preprocessed data. The goal is to identify the algorithm that best suits our dataset and yields the highest performance.
6.1 Model Selection and Training
Step 1: Logistic Regression
We start with Logistic Regression, a simple yet effective classification algorithm. The classification report provides insights into the model's precision, recall, and F1-score.
# Logistic Regression
log_reg = LogisticRegression(max_iter=1000)
log_reg.fit(X_train, y_train)
y_pred_log_reg = log_reg.predict(X_test)
print('Logistic Regression classification report:\n', classification_report(y_test, y_pred_log_reg))
Step 2: Decision Tree
Then Decision Trees. They are employed with specific hyperparameters. The classification report helps assess the model's performance.
# Decision Tree
dt = DecisionTreeClassifier(max_depth=10, min_samples_split=0.01, min_samples_leaf=0.01, random_state=42, criterion='entropy')
dt.fit(X_train, y_train)
y_pred_dt = dt.predict(X_test)
print('Decision Tree classification report:\n', classification_report(y_pred_dt, y_pred_log_reg))
Step 3: Random Forest
Then the Random Forest model which is a robust ensemble learning method. We evaluate its performance using the classification report.
# Random Forest
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print('Random Forest classification report:\n', classification_report(y_pred_rf, y_pred_log_reg))
Step 4: XGBoost
The we also try XGBoost which is a gradient boosting algorithm. We assess its performance through the classification report.
# XGBoost
xgb_clf = xgb.XGBClassifier()
xgb_clf.fit(X_train, y_train)
y_pred_xgb = xgb_clf.predict(X_test)
print('XGBoost classification report:\n', classification_report(y_pred_xgb, y_pred_log_reg))
Step 5: LightGBM
We also try LightGBM, another gradient boosting algorithm, it is employed and evaluated using the classification report.
# LightGBM
lgb_clf = lgb.LGBMClassifier()
lgb_clf.fit(X_train, y_train)
y_pred_lgb = lgb_clf.predict(X_test)
print('LightGBM classification report:\n', classification_report(y_pred_lgb, y_pred_log_reg))
Step 6: MLPClassifier (Neural Network)
And finally an MLPClassifier, representing a neural network, is utilised, and its performance is evaluated through the classification report.
# MLPClassifier (Neural Network)
mlp_classifier = MLPClassifier(hidden_layer_sizes=(500,), max_iter=1000, random_state=42)
mlp_classifier.fit(X_train, y_train)
mlp_y_pred = mlp_classifier.predict(X_test)
print('MLPClassifier classification report:\n', classification_report(y_test, mlp_y_pred))
6.2 Model Evaluation and Prediction
Step 7: Model Evaluation with Confusion Matrices
Confusion matrices are visualised to further evaluate the models.
# Confusion matrices for Decision Tree, Random Forest, and LightGBM
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix(y_pred_dt, y_pred_log_reg), annot=True, fmt='d')
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix(y_pred_rf, y_pred_log_reg), annot=True, fmt='d')
plt.figure(figsize=(10, 7))
sns.heatmap(confusion_matrix(y_pred_lgb, y_pred_log_reg), annot=True, fmt='d')
Step 8: Model Deployment and Prediction
The below code demonstrates how to load saved processors (encoder and scaler) and process new data for prediction using the trained MLPClassifier, which is the model I chose to proceed with among the six trained models. I had my reasons to choose that for the sake of this article but you can choose another model based on which model performed best for you or try out other techniques like the ensemble model which combines the power of various ML algorithms into one.
# Load saved processors (encoder and scaler)
def load_processors():
with open('encoder.pkl', 'rb') as f:
encoder = pickle.load(f)
with open('scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
return encoder, scaler
# Process new data using saved processors
def process_new_data(new_data):
encoder, scaler = load_processors()
# ... (omitted for brevity)
# Example of predicting with a new data point
_dt = train.head(1).drop(['uniqueid', 'bank_account'], axis=1)
__dt_processed = process_new_data(_dt)
prediction = mlp_classifier.predict(__dt_processed.values)
prediction
In the model development and Evaluation phase, we systematically explored various algorithms, evaluate their performance, and select the most suitable model for the given dataset. The chosen model can then be used for predictions on new data.
7. Model Saving and Deployment
7.1 Model Saving (LightGBM as an Example)
The code below demonstrates how to save the trained LightGBM model as a pickle file (lightgbm_model.pkl). This file can be later loaded to make predictions on new data without retraining the model.
# Saving the LightGBM model using pickle
import pickle
# Assuming lgb_clf is the trained LightGBM model
with open('lightgbm_model.pkl', 'wb') as model_file:
pickle.dump(lgb_clf, model_file)
7.2 Model Deployment with Streamlit
Before deploying the Streamlit app, you need to initiate a Streamlit app. Create a new Python script (e.g., app.py) and use the following code as a starting point:
In this stage the code below is just sample code to show you how to deploy you model to streamlit as an application, you can modify it to your liking and if you are new to streamlit I recommend their documentation for further knowledge, it is to use and understand.
# app.py
import streamlit as st
import pickle
import pandas as pd
# Load the LightGBM model
with open('lightgbm_model.pkl', 'rb') as model_file:
lgb_model = pickle.load(model_file)
# Function to process new data for prediction
def process_new_data(new_data):
# ... (omitted for brevity, use the process_new_data function from previous steps)
# Streamlit App
def main():
st.title("Financial Inclusion Prediction App")
# Sidebar
st.sidebar.header("User Input")
# Create input elements for user to input data
# Example: Load a sample data point for prediction
sample_data = train.head(1).drop(['uniqueid', 'bank_account'], axis=1)
processed_data = process_new_data(sample_data)
# Prediction with LightGBM model
prediction = lgb_model.predict(processed_data.values)
# Display the prediction
st.subheader("Prediction Result:")
st.write("Predicted Bank Account Access:", prediction[0])
if __name__ == '__main__':
main()
7.3 Streamlit App Appearance
You can customize the appearance of your Streamlit app by modifying the code within the main() function. Add Streamlit elements like sliders, text input, or dropdowns for user interaction. Here's an example:
# Inside the main() function
user_input = st.sidebar.number_input("Enter Household Size", min_value=1, max_value=10, step=1)
user_age = st.sidebar.number_input("Enter Respondent Age", min_value=18, max_value=100, step=1)
# ... (other input elements)
# Process user input for prediction
user_data = pd.DataFrame({
'household_size': [user_input],
'age_of_respondent': [user_age],
# ... (other input features)
})
processed_user_data = process_new_data(user_data)
prediction = lgb_model.predict(processed_user_data.values)
# Display the prediction
st.subheader("Prediction Result:")
st.write("Predicted Bank Account Access:", prediction[0])
Feel free to customize the Streamlit app based on your preferences and user interaction requirements.
7.4 Running the Streamlit App Locally
To run the Streamlit app locally, open a terminal, navigate to the directory containing app.py, and run:
streamlit run app.py
This command will launch a local development server, and you can access the app in your web browser at the provided URL.
Deploying the app to a production environment would involve additional steps, such as hosting on a cloud platform.
Now, you have a Streamlit app ready for user interaction and prediction using the saved LightGBM model!
Here is the Preview of how the Streamlit app might look like:
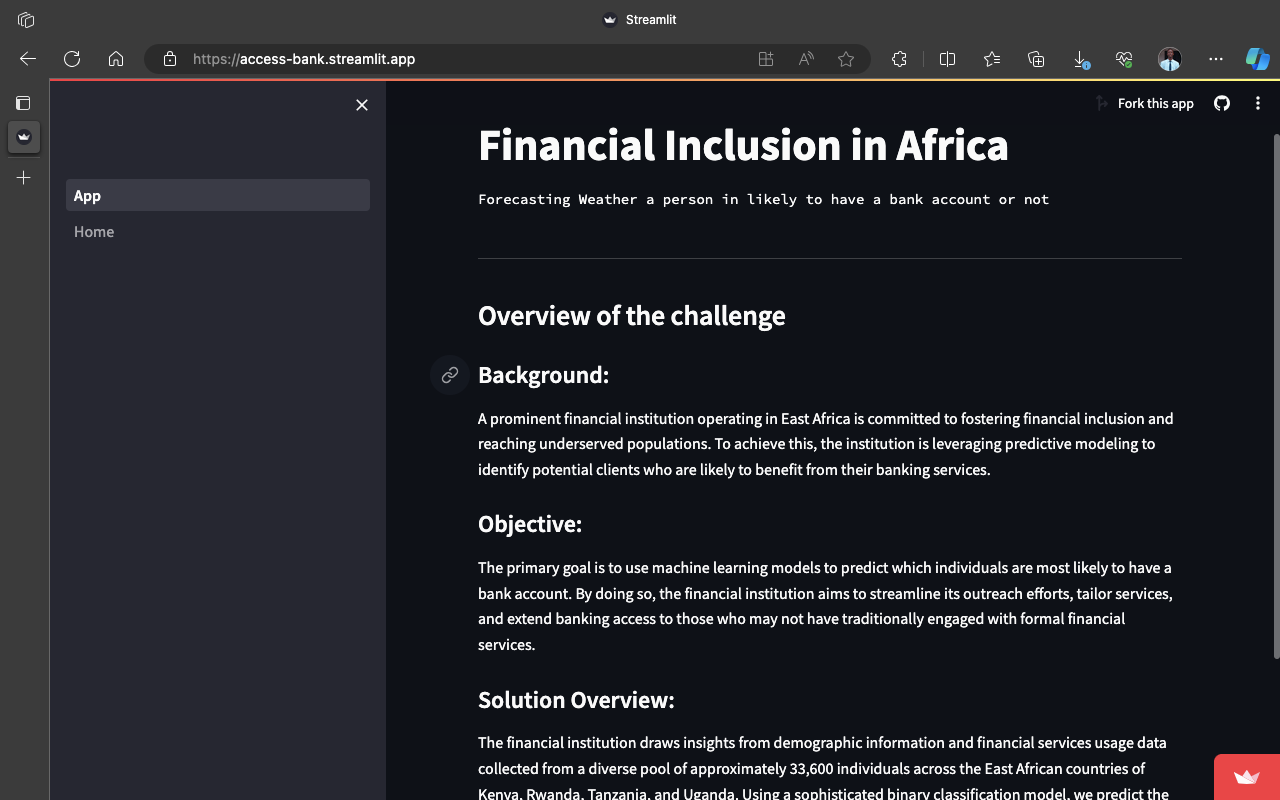
8. Conclusion
In conclusion, This project was prepared by our AI community UDSM AI Community on predicting bank account access in East Africa showcases the power of data science in addressing real-world challenges. By leveraging machine learning algorithms, we have provided valuable insights into factors influencing financial inclusion. The LightGBM model, identified as the top performer, holds promise for informing targeted initiatives. The Streamlit-based web application adds a practical dimension, offering a user-friendly tool for stakeholders. We invite the community to explore our GitHub repository here and contribute to fostering financial inclusion in the region. This project marks a step toward a more inclusive and empowered future.
Visit the GitHub repository for the complete project code and resources.